Voice AI Evaluation Insights & Testing Guides
Practical guides, research, and field reports on testing, evaluating, and monitoring AI voice agents — from the Evalgent team.
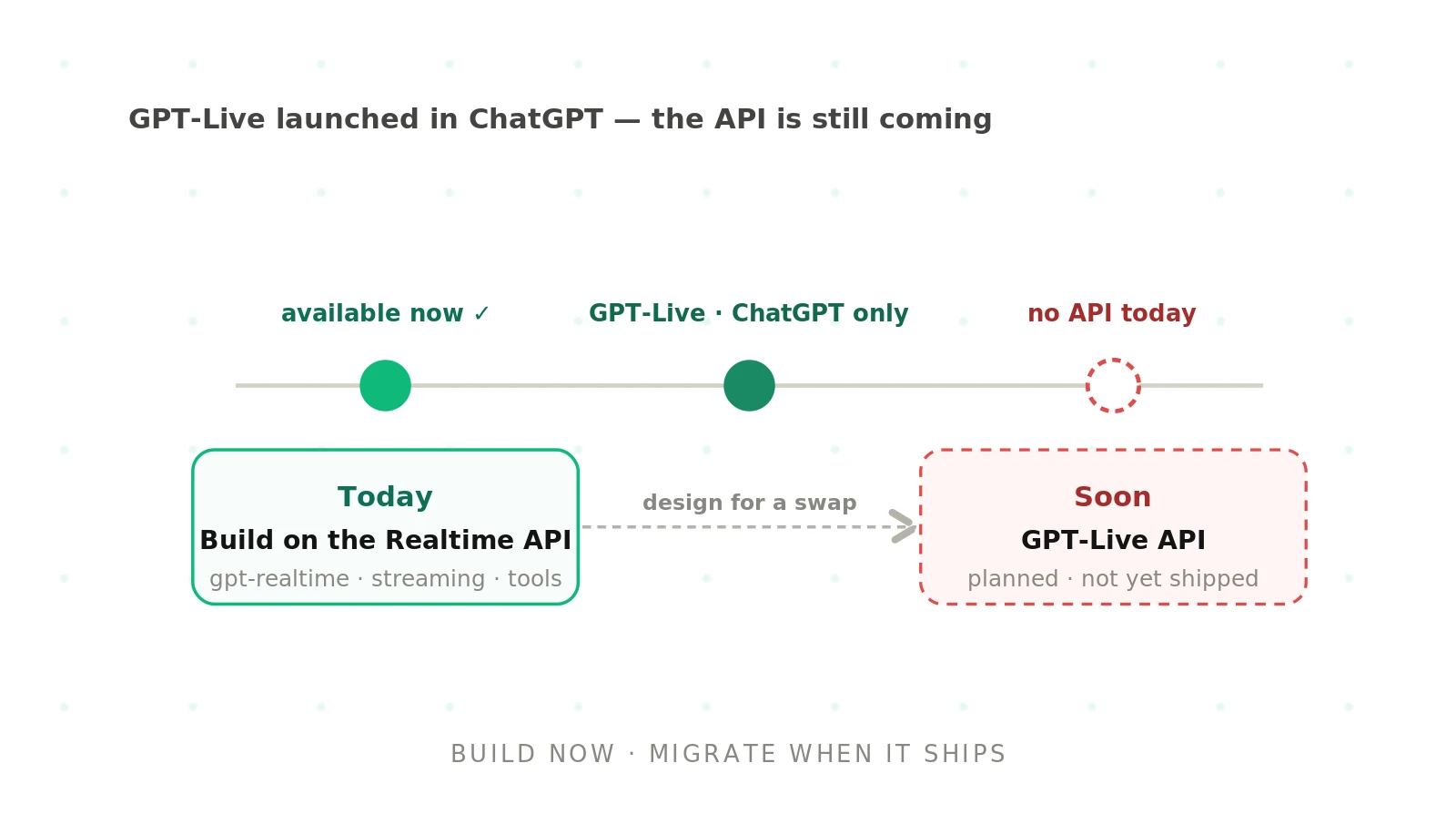
How to build voice agents with GPT-Live (and what to do until the API ships)
GPT-Live changes how you architect a voice agent, not just which model you call. Learn what full-duplex changes and what to build until the API ships.
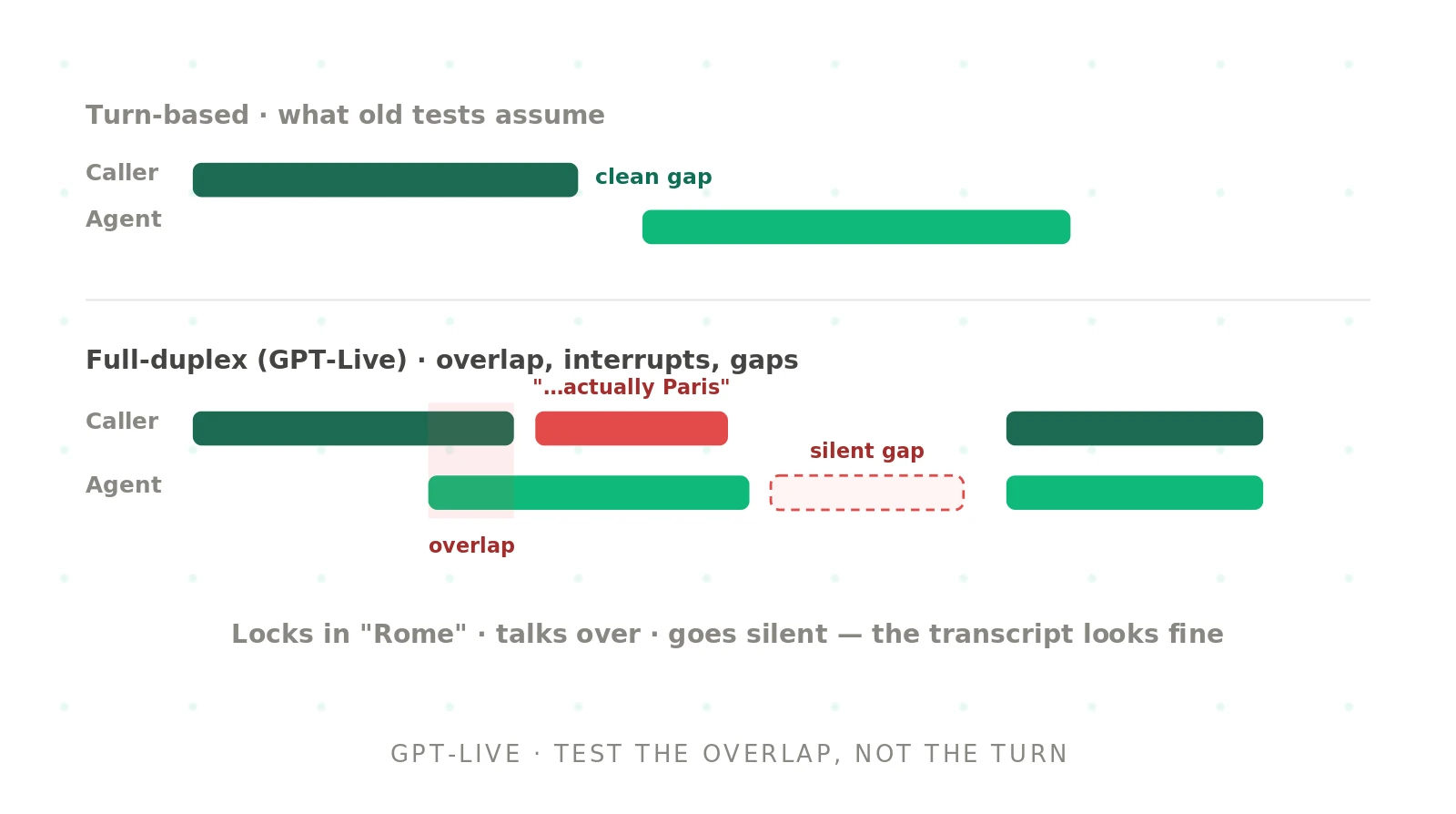
How to test GPT-Live voice agents: the new failure modes of full-duplex
GPT-Live is full-duplex, so it breaks the clean-turn assumption most tests rely on. Learn the new failure modes and how to test a GPT-Live voice agent.

Voice agent testing for food ordering: order accuracy, modifiers, and noise
Food ordering voice agents take orders over noisy lines full of modifications. Learn how to test one for order accuracy and noise robustness.

Voice agent testing for appointment scheduling: booking, dates, and tools
Scheduling voice agents book, reschedule, and cancel across calendars and timezones. Learn how to test an appointment scheduling voice agent for accuracy.

Voice agent testing for insurance: claims, quotes, and accuracy
Insurance voice agents handle claims, quotes, and policy questions. Learn how to test an insurance voice agent for accuracy and safe escalation.

Voice agent testing for financial services: authentication, fraud, and compliance
Financial services voice agents handle authentication, money movement, and disclosures. Learn how to test a banking voice agent for security.
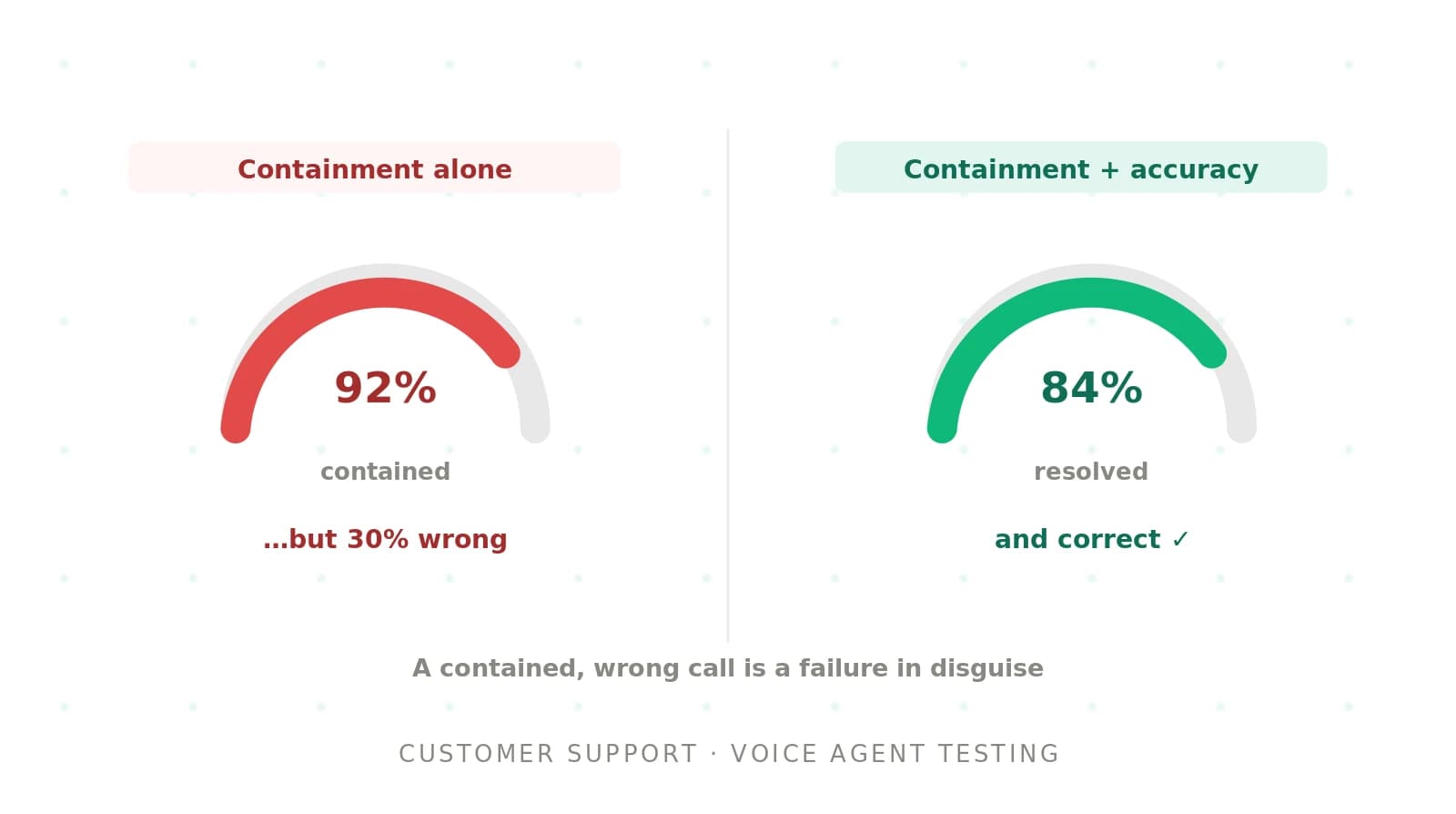
Voice agent testing for customer support: containment, accuracy, and escalation
Customer support voice agents live or die on containment and accuracy. Learn how to test one for resolution, grounding, and clean escalation.

Voice agent testing for collections: FDCPA, disclosures, and tone
Collections voice agents must follow FDCPA rules, verify the right party, and stay compliant. Learn how to test a debt collection voice agent.

Voice agent testing for healthcare: HIPAA, safety, and reliability
Healthcare voice agents handle PHI, triage, and scheduling. Learn how to test them for HIPAA compliance, patient safety, and reliability.