Blog
Page 2 of 3
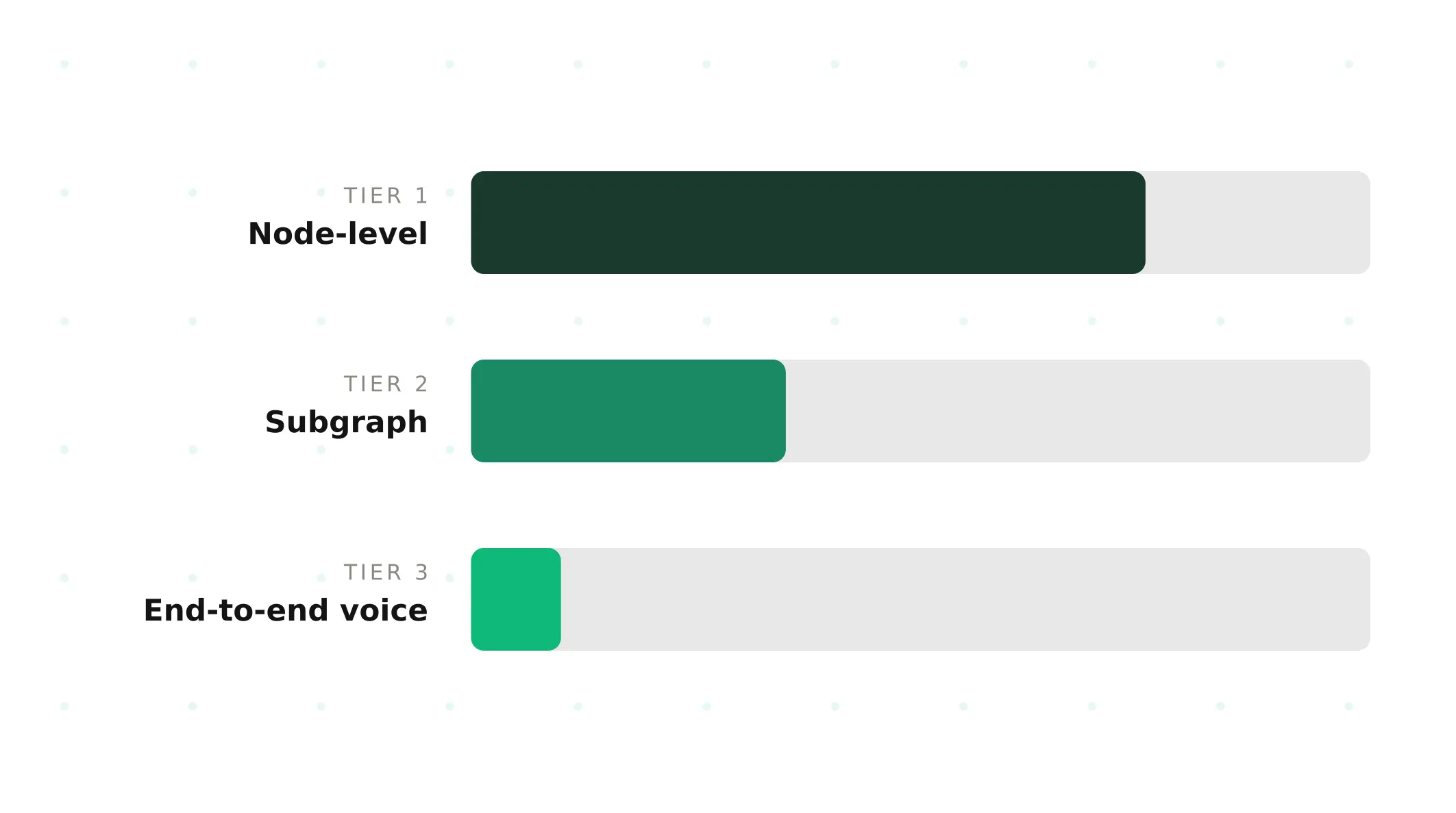
Testing Graph-Based Voice Agents: The Three-Tier Model
Testing graph-based voice agents requires three tiers — node, subgraph, end-to-end voice. Most teams stop at tier one. Here's what production-grade looks like.

Should You Build a Graph-Based or Prompt-Based Voice Agent?
Graph-based vs prompt-based voice agents: a decision framework. Five questions, a clear matrix, and three hybrid patterns most teams actually ship.
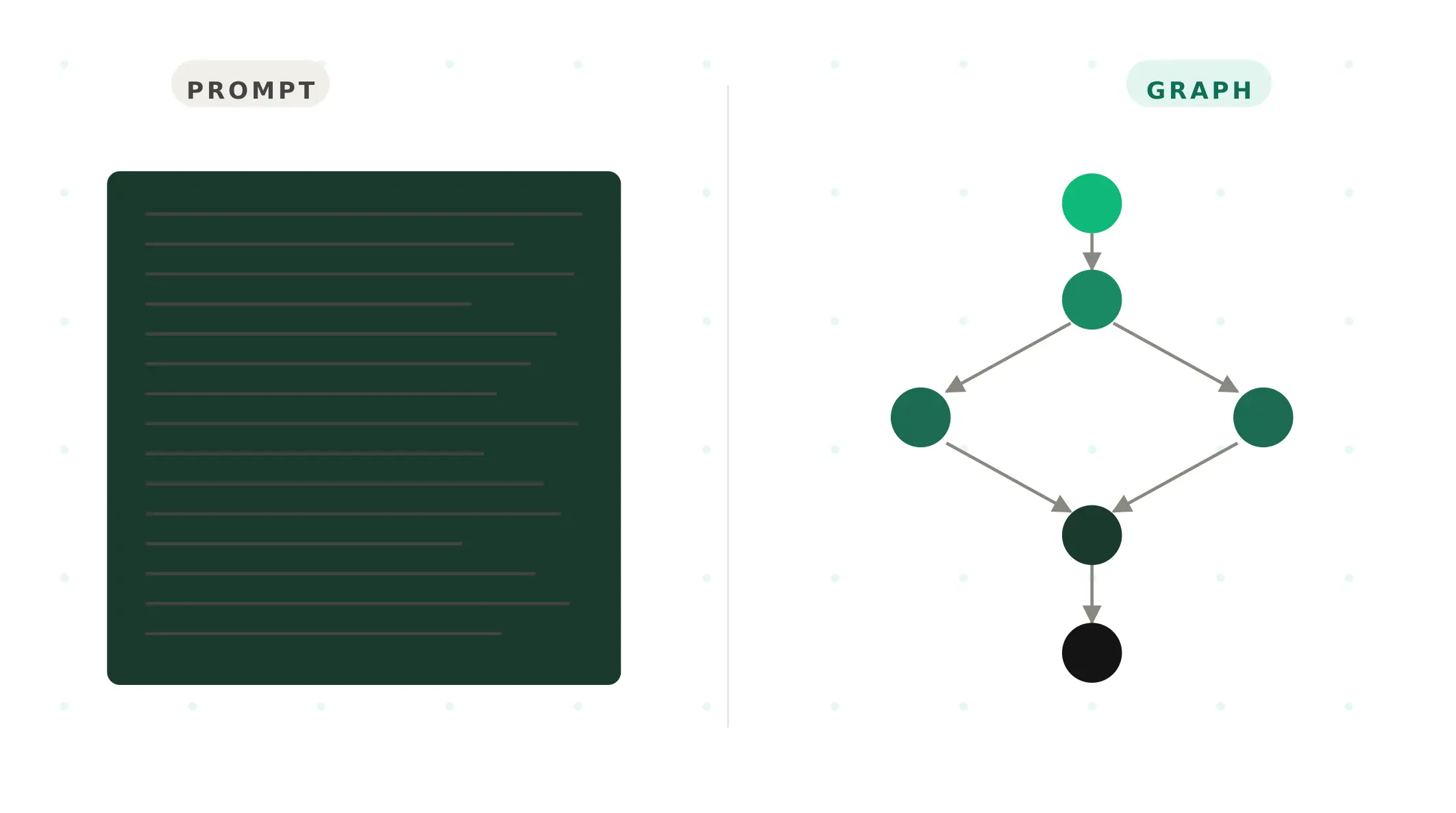
Why Production Voice Agents Are Becoming Graphs, Not Prompts
Graph-based voice agents externalise control flow that prompt-based agents trust the LLM to handle. Why this is the architecture winning production deployments.
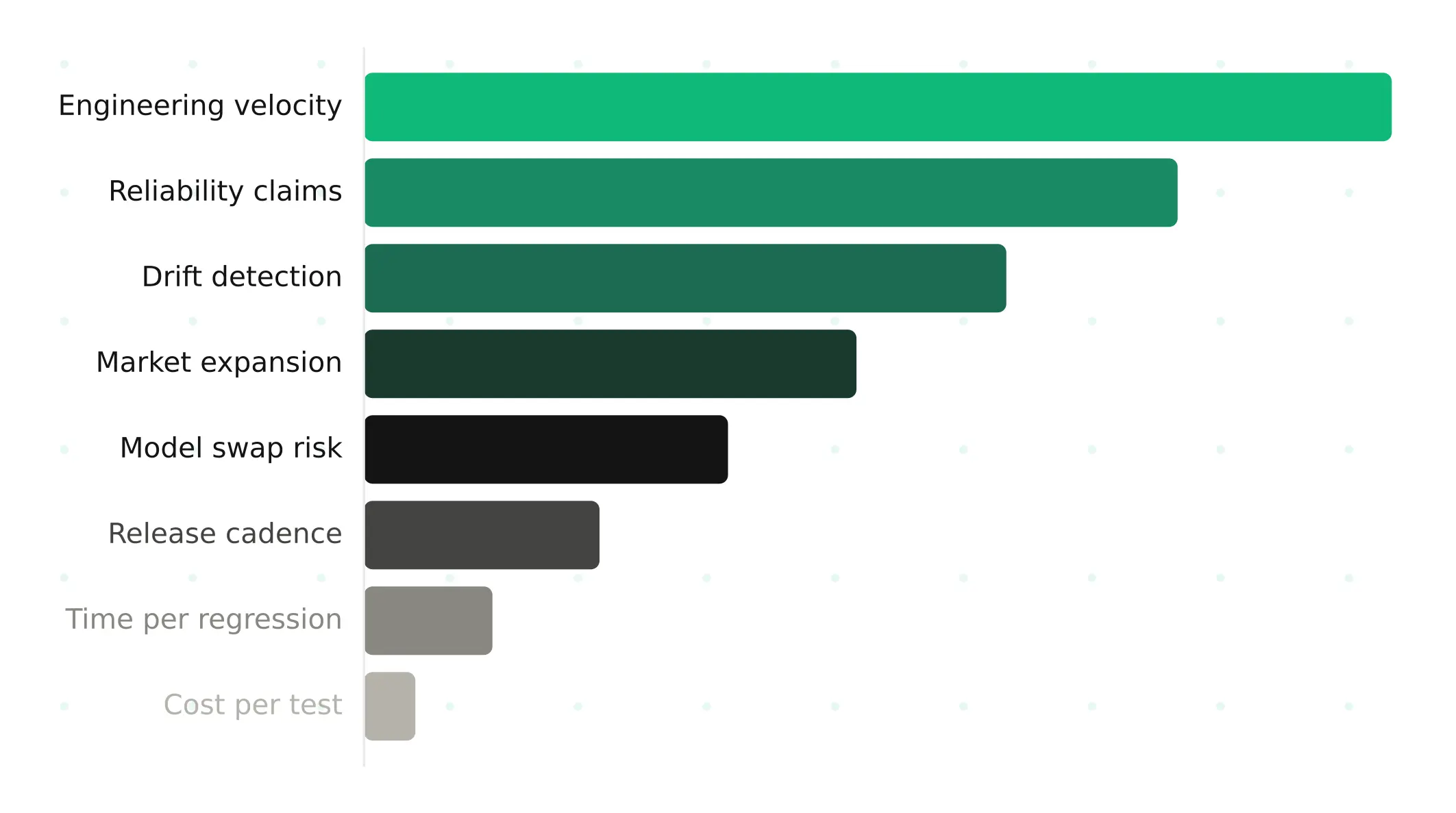
The ROI of AI Voice Agent Testing Isn't What You Think It Is
Cost-per-test is the wrong way to measure voice agent testing ROI. Six capabilities that change how teams ship voice AI — and what they're worth.

You don't read AI-generated code. Why are you listening to every call?
Nobody reads AI-generated code anymore. Tests became mandatory. Voice agents are next — eval-driven development is how reliable voice AI gets shipped.

AI Agent Testing vs Voice Agent Testing: What General Tools Miss for Voice
AI agent testing measures text outputs. Voice agent testing measures behaviour through an acoustic pipeline. Five failure categories general tools miss.
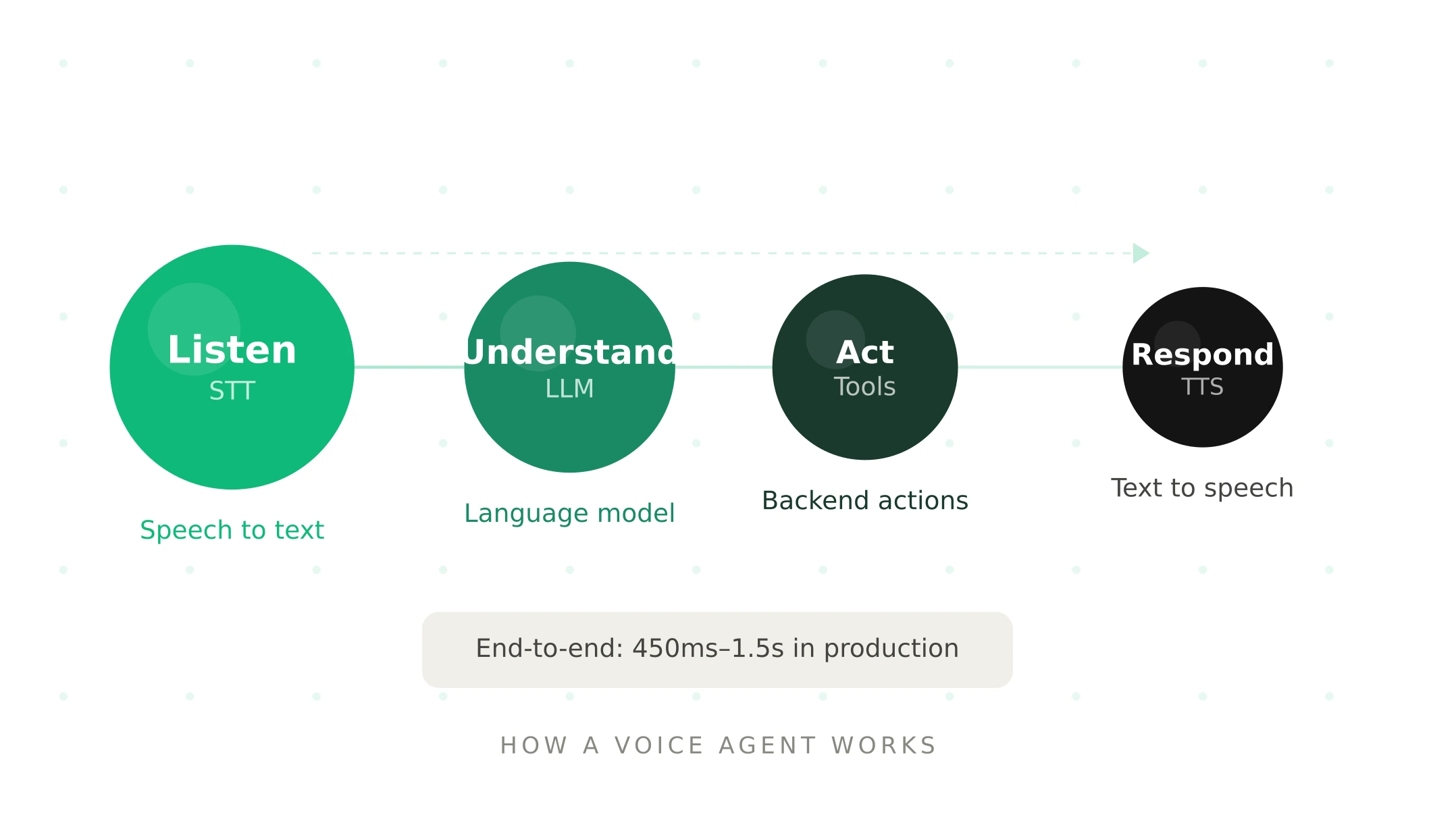
What is a voice agent? The complete guide
What is a voice agent? How it works, how it differs from IVR and chatbots, use cases by industry, and what production-ready deployment actually requires.

Voice agent stack: the complete guide
Voice agent stack guide: STT, LLM, TTS, orchestration, and telephony. Latency budget, cost per layer, build vs buy, and what to test before production.
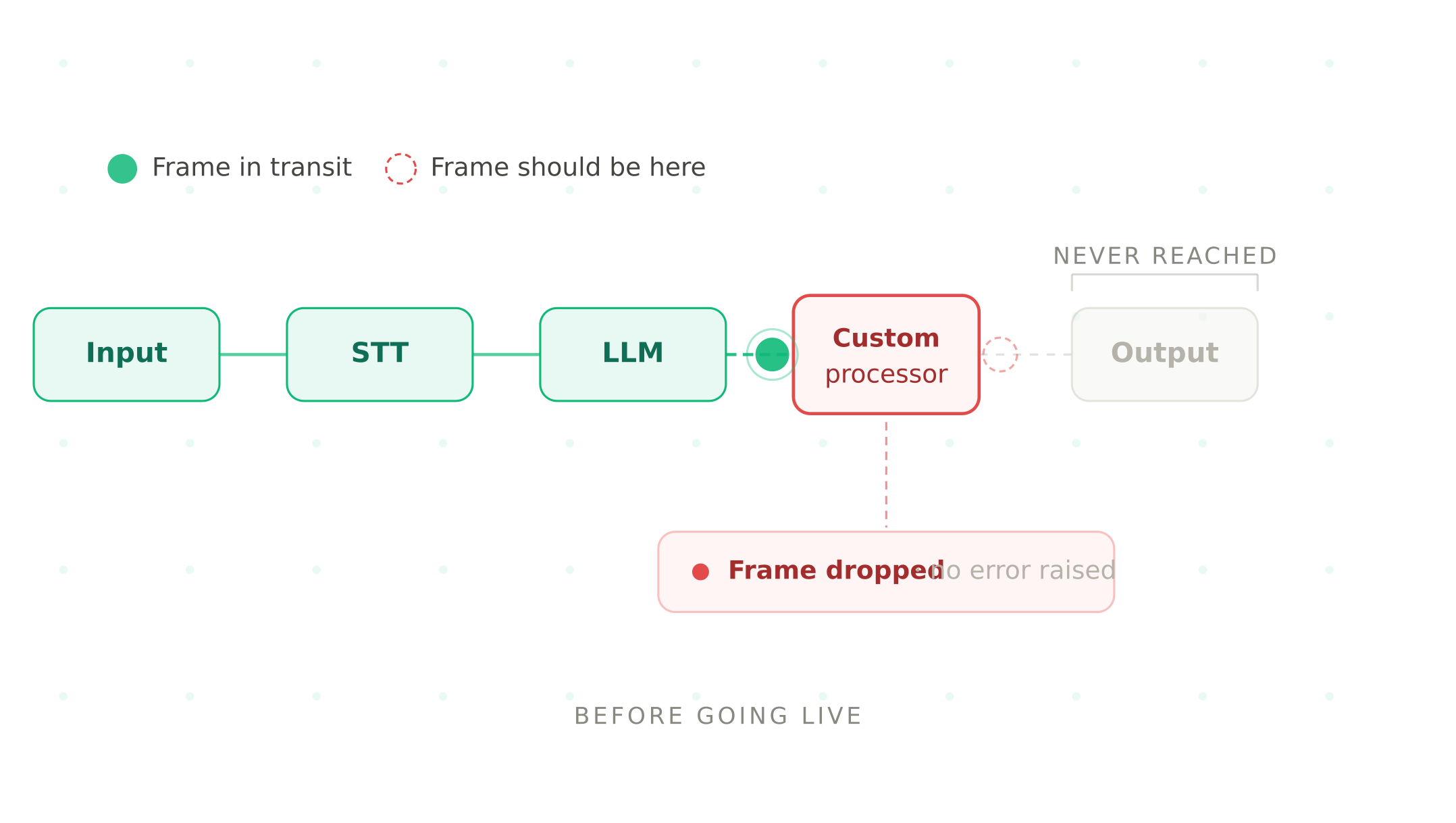
Pipecat voice agent testing guide: what to check before going live
Test your Pipecat voice agent before going live. VAD, frame errors, transport, Flows state machine, and pipeline regression after every processor change.