Test your voice agent
Voice agent stack: the complete guide

Voice agents are no longer experimental. The speech recognition market is projected to reach $29.28 billion by 2026, and AI voice agent deployments now span customer service, healthcare, financial services, and every industry with a phone channel. They handle appointment booking, support triage, lead qualification, payment processing, and complex multi-turn conversations that rigid IVR systems could never manage.
Yet most teams building their first voice agent encounter the same problem: the technology feels simple in a demo and complex in production. The reason is almost always the same — they built one layer and assumed the others would follow. A voice agent is not a single product. It is five distinct layers that must work together in real time, each with its own providers, costs, latency contributions, and failure modes.
Understanding the stack — what each layer does, how they connect, and what testing each layer requires — is what separates a voice agent that holds up in production from one that fails in ways the demo never predicted.
What a voice agent actually is
Before mapping the stack, it helps to be precise about what a voice ai agent is and what it is not.
What it is not: An IVR (interactive voice response) system routes callers through predefined menus using touch-tone or simple keyword matching. A chatbot handles text conversations without real-time audio. A voice bot that reads a fixed script is not a voice agent. None of these understand natural language in real time or generate contextual responses.
What it is: A voice agent is a conversational ai agent that understands and responds to human speech in real time. It handles complex, multi-turn conversations, adapts to natural language, calls external tools and APIs mid-conversation, and maintains context across a full interaction. It behaves more like a skilled call centre operator than a menu system.
Two architecture patterns
There are two ways to wire the stack. Understanding the difference is the first decision every team faces.
Cascading pipeline (STT → LLM → TTS): The user speaks. STT transcribes the audio to text. The LLM receives the text, determines intent, generates a response, and optionally calls a tool. TTS converts the response to audio. The orchestration layer manages the handoffs. According to AssemblyAI's voice agent architecture guide, this is the most widely deployed pattern in production: modular, debuggable, provider-swappable, and telephony-compatible.
Speech-to-speech (S2S): A single large model handles the entire process from audio input to audio output — bypassing the STT→LLM→TTS chain entirely. OpenAI Realtime API (gpt-realtime-1.5, GA since August 2025) and Google Gemini 3.1 Flash Live (Preview launched March 2026) are the leading S2S options. S2S excels on conversational naturalness and raw latency when conditions are ideal. It struggles with telephony-grade audio (PSTN codec mismatch), complex tool calling, compliance requirements, and cost predictability at scale.
For most production deployments in 2026 — especially phone-based agents — the cascading pipeline is the more reliable choice. For web-based conversational interfaces where audio quality is consistent, S2S is increasingly viable.
The five layers of a voice agent stack
Layer 1 — STT: the ears
Speech-to-text is what converts the user's audio into text the LLM can process. It is the first point of contact with real-world speech and the layer most affected by real-world conditions: background noise, regional accents, fast speech, disfluency, and variable audio quality.
What to know: STT is measured in Word Error Rate (WER) — the percentage of words transcribed incorrectly. But benchmark WER on clean audio does not predict production WER on real calls. A model achieving 5% WER in controlled conditions may produce 20–35% WER in noisy environments. The gap between benchmark and production WER is one of the most common sources of silent voice agent failures.
Provider options:
| Provider | Model | Latency | Pricing | Best for |
|---|---|---|---|---|
| Deepgram | Nova-3 | sub-300ms | $0.0077/min streaming | Real-time agents, cost efficiency |
| AssemblyAI | Universal-2 | Competitive | $0.01+/min | Accuracy, broad language coverage |
| OpenAI | GPT-4o Transcribe | Higher TTFB | $6/1,000 min | Accuracy-first, batch applications |
| Chirp 2 | Competitive | $16/1,000 min | Enterprise, GCP ecosystem | |
| Whisper | Large V3 | Variable | Free (self-hosted) | Cost-sensitive, offline processing |
STT also includes Voice Activity Detection (VAD) — the mechanism that determines when a user starts and stops speaking. VAD configuration is critical: too sensitive and background noise triggers false detections; too conservative and the agent misses turn completions. In self-assembled stacks (Pipecat, LiveKit), VAD is configurable and must be calibrated for your acoustic environment before launch.
Layer 2 — LLM: the brain
The large language model determines what the voice agent says. It receives the transcript from STT, maintains conversation context, determines user intent, generates a response, and decides whether to call an external tool or API.
What to know: LLMs for voice agents have different requirements from LLMs for text applications. Latency is critical — every millisecond of LLM inference adds to the total conversation delay. Time to first token (TTFT) matters more than total generation time, because TTS can begin speaking as soon as the first tokens arrive. Context window management also matters: conversation history grows with each turn, increasing token cost and inference time across a long call.
Provider options:
| Provider | Model | TTFT | Pricing | Best for |
|---|---|---|---|---|
| OpenAI | GPT-4o | ~200ms | ~$0.02/min | Balanced quality and speed |
| Anthropic | Claude 3.5 Haiku | Competitive | ~$0.01/min | Instruction following, complex flows |
| Gemini 1.5 Flash | Fast | ~$0.01/min | Cost-efficient at scale | |
| Groq | Llama-3 | sub-100ms | ~$0.005/min | Lowest latency, open models |
| Ollama | Various | Variable | Self-hosted | Cost control, data residency |
Tool calling is the mechanism through which voice agents take actions — booking appointments, querying databases, processing payments, updating CRMs. When the LLM determines an action is required, it generates a structured tool call that the orchestration layer executes. Tool call correctness — whether the downstream system receives and processes the right parameters — is one of the most dangerous silent failure modes in production.
Layer 3 — TTS: the voice
Text-to-speech converts the LLM's response into audio the user hears. It is the most perceptually impactful layer — users form an immediate impression of the agent's quality based on voice naturalness, speed, and expressiveness. A technically correct response spoken in a robotic voice undermines trust faster than a slightly imperfect transcript.
What to know: TTS latency is measured in time to first audio byte — how quickly the first audio frame is produced after receiving text. Streaming TTS is critical: the TTS model should begin generating audio from the first sentence fragment while the LLM is still producing the rest of the response. Non-streaming TTS waits for the complete text before beginning synthesis, adding hundreds of milliseconds to total TTFB.
Provider options:
| Provider | Model | TTFB | Quality | Pricing |
|---|---|---|---|---|
| ElevenLabs | Turbo v2.5 | ~100ms | Best-in-class expressiveness | $0.08/min (Business) |
| Cartesia | Sonic-3 | sub-100ms | High quality, fastest | ~$0.05–0.07/min |
| Deepgram | Aura-2 | sub-200ms | Natural, entity-aware | Bundled in Voice Agent API |
| OpenAI | TTS-1 | ~300ms | Good, consistent | ~$0.03/min |
| Azure | Neural TTS | Variable | Enterprise-grade, multilingual | ~$0.016/min |
Barge-in handling — the ability for users to interrupt the agent mid-response — is managed at the intersection of TTS and orchestration. When a user starts speaking while the agent is still talking, the orchestration layer must detect the interruption, stop TTS playback, and begin processing the new input. Poor barge-in handling is one of the most commonly reported production failures because it was not tested with realistic interruption patterns before launch.
Layer 4 — Orchestration: the conductor
Orchestration is the layer that coordinates the other four. It manages the real-time flow between components, handles turn-taking, processes tool call results, maintains conversation context, and recovers from component failures.
What to know: Orchestration is the hardest layer to get right and the layer most teams underestimate. The core challenges — turn detection, barge-in handling, tool call routing, error recovery, context management, audio routing — each require careful tuning. A misconfigured turn detection model produces the most commonly reported production failure: the agent starts speaking while the user is still mid-sentence, or waits too long after the user finishes.
Options:
| Approach | Examples | Best for |
|---|---|---|
| Managed platform | Vapi ($0.05/min), Retell ($0.07+/min) | Fast deployment, less configuration |
| Open-source framework + cloud | LiveKit Agents ($0.01/min), Pipecat Cloud | Control + managed infrastructure |
| Open-source self-hosted | LiveKit, Pipecat | Maximum control, cost at scale |
| Bundled API | Deepgram Voice Agent API ($4.50/hr), AssemblyAI ($4.50/hr) | Single-vendor simplicity |
The orchestration layer is where managed platforms provide the most value — they handle turn detection defaults, interruption logic, scaling, and reliability so you can focus on conversation design. The cost is reduced control and higher per-minute fees.
Layer 5 — Telephony: the connection
Telephony is how your voice agent connects to phone networks — receiving inbound calls and making outbound calls through the PSTN (public switched telephone network). It is the layer most developers think about last and most enterprise buyers think about first.
What to know: Telephony introduces constraints that WebRTC testing does not reveal. PSTN audio uses different codecs (G.711, G.722) than WebRTC (Opus), and the transcoding step adds latency and introduces acoustic characteristics that affect STT accuracy. A voice agent that performs well in browser-based testing may produce elevated word error rates on actual phone calls due to codec processing.
Options:
| Provider | Type | Pricing | Best for |
|---|---|---|---|
| Twilio | SIP trunk / numbers | ~$0.0085/min | Ecosystem, global coverage |
| Telnyx | SIP trunk / numbers | ~$0.004/min | Cost efficiency |
| LiveKit Phone Numbers | Native (2025) | Competitive | LiveKit Agents deployments |
| Vapi/Retell built-in | Managed | Included in platform fee | Managed platform teams |
| Bring your own SIP | Any SIP provider | Variable | Existing VoIP infrastructure |
The latency budget — sub-300ms or it feels broken
Every voice ai agent lives or dies on one number: the time from the user finishing their turn to the first syllable of the agent's response. This is Time to First Byte (TTFB) — the most important metric in voice agent quality.
According to the LiveKit 2026 voice agent playbook, the thresholds are clear:
- Below 300ms: feels human — natural conversation pace
- 300–600ms: sluggish but acceptable — users notice but tolerate
- Above 600ms: users revert to touch-tone mental models and start pressing keys
- Above 1.5s: hang-up rates increase significantly
The challenge: published industry P95 latency across millions of real calls sits at 1.4–1.7s. P99 runs 3–5s. The sub-300ms target is achievable — but only with streaming at every stage, co-located infrastructure regions, and pre-warmed model contexts.
Where latency comes from
| Layer | Typical contribution | Optimised contribution |
|---|---|---|
| VAD / turn detection | 50–200ms | 50ms (streaming VAD) |
| STT (first transcript) | 100–300ms | 100ms (streaming, Deepgram Nova-3) |
| LLM (first token) | 150–500ms | 100ms (Groq, streaming) |
| TTS (first audio) | 100–300ms | 80ms (Cartesia Sonic-3) |
| Network hops | 50–200ms | 30ms (co-located) |
| Total | 450–1,500ms | ~360ms |
Streaming vs sequential
The difference between a 1,500ms and a 360ms voice agent is not hardware — it is architecture. A sequential pipeline waits for each stage to complete before passing data to the next: STT completes → LLM starts → LLM completes → TTS starts. Every wait is cumulative.
A streaming pipeline runs stages in parallel. STT sends partial transcripts to the LLM as they arrive. The LLM begins generating before the transcript is complete. TTS begins synthesising from the first sentence fragment before the LLM finishes. The user hears the response while the pipeline is still processing — this is the architecture that makes sub-500ms TTFB possible at production scale.
The voice agent latency breakdown matters not just for user experience but for reliability. At P95, latency spikes in any layer stack additively — a 600ms STT spike combined with a 400ms LLM spike and a 300ms TTS spike produces a 1.3s total delay that pushes call abandonment.
Voice agent stack cost breakdown
The voice agent cost per minute breakdown depends entirely on which providers you choose and whether you use a managed platform or assemble your own stack.
Self-assembled stack — illustrative configuration:
| Layer | Provider | Cost/min |
|---|---|---|
| STT | Deepgram Nova-3 | $0.0077 |
| LLM | GPT-4o | ~$0.020 |
| TTS | Cartesia Sonic-3 | ~$0.060 |
| Orchestration | LiveKit Cloud | $0.010 |
| Telephony | Telnyx | $0.004 |
| Total | ~$0.10/min |
Managed platform — Vapi:
| Component | Cost/min |
|---|---|
| Vapi platform | $0.05 |
| LLM (BYOK) | ~$0.02–0.20 |
| STT (BYOK) | ~$0.004–0.017 |
| TTS (BYOK) | ~$0.011–0.065 |
| Telephony | ~$0.004–0.014 |
| Total | ~$0.09–0.35/min |
The stt tts llm voice agent pipeline cost rule: at low volume (below ~10,000 minutes per month), managed platforms are often cheaper when you account for the engineering time to build and maintain a self-assembled stack. Above ~10,000 minutes per month, the open-source framework path undercuts managed platforms by 60–80% per call. This is the break-even point for the build vs buy decision.
According to Deepgram's pricing documentation, per-second billing (rather than per-minute rounding) adds another cost advantage for short conversational utterances — a meaningful factor in high-volume contact centre deployments.
Build vs buy: how to choose a voice agent platform
The stt llm tts voice agent pipeline can be assembled from scratch or purchased as a managed service. The right answer depends on volume, engineering resources, and how much of the infrastructure you need to own.
| Factor | Choose managed (Vapi, Retell) | Choose open-source (LiveKit, Pipecat) |
|---|---|---|
| Time to first call | Hours | Days to weeks |
| Engineering required | Low | High |
| Monthly volume | Below 10K minutes | Above 10K minutes |
| Provider flexibility | Medium (BYOK) | Maximum |
| Concurrency management | Managed | Self-managed |
| Telephony | Included or easy to add | DIY or LiveKit SIP |
| Cost at scale | Higher per-minute | 60–80% cheaper |
| Testing surface | Webhooks, prompts | Full pipeline + VAD + frames |
For a detailed comparison of managed platforms, see the Vapi testing guide and the LiveKit testing guide. The key distinction: managed platforms handle infrastructure reliability. You still own conversation reliability — scenario coverage, user behaviour testing, and regression testing — regardless of which platform you choose.
What to test at each layer before production
Understanding the voice agent stack components is not enough. Every layer has specific failure modes that only appear under real-world conditions — and that demos, internal testing, and UAT systematically miss.
The most important insight in voice agent evaluation is this: voice agents fail not because they are incapable, but because they were tested at a single point instead of across a spectrum of human behaviour.
STT layer testing: Noise degradation (WER under real acoustic conditions), accent coverage, disfluency handling, streaming latency at P95 under concurrent load. See the Deepgram STT testing guide for a full methodology.
LLM layer testing: Intent classification accuracy under ambiguous input, tool call parameter correctness, context management across long calls, regression after every prompt or model change.
TTS layer testing: Latency at P95 under concurrent load, barge-in interruption handling under realistic speech patterns, expressiveness and intelligibility on domain-specific vocabulary.
Orchestration layer testing: Turn detection under noise and disfluency, webhook failure path handling, state machine completeness (for structured flows), regression after every configuration change.
Telephony layer testing: PSTN codec handling (separate from WebRTC testing), SIP integration end-to-end, DTMF input handling, call setup failure paths.
The testing methodology that covers all five layers systematically — running synthetic callers with parameterised acoustic profiles, behavioural conditions, and concurrent load across every scenario — is what closes the gap between demo confidence and production confidence.
Pre-launch checklist for any voice agent stack
Before any voice agent goes live, regardless of which stack you have assembled:
1. Run full scenario suite — every designed conversation flow, end-to-end. Task completion ≥90% is the minimum threshold.
2. Test across acoustic profiles — clean audio, 65dB noise, accent variants representative of your actual user base.
3. Test tool call correctness — verify downstream system state, not transcript quality.
4. Measure P95 latency under concurrent load — not P50. Single-session testing hides P95 failures.
5. Test telephony separately from WebRTC — PSTN codec handling requires real phone calls.
6. Run regression suite — before every deployment, against a known-good baseline.
7. Set production monitoring baselines — task completion rate, escalation rate, P95 TTFB, repeat contact rate. Document before launch, not after.
Summary
A voice agent stack has five layers: STT, LLM, TTS, orchestration, and telephony. Each contributes latency, cost, and its own failure modes.
Testing each layer systematically before production is what separates a demo from a deployment.
Frequently asked questions
What is a voice agent?
A voice agent is a real-time AI system that understands and responds to human speech using a stack of AI models. It handles multi-turn conversations, calls external tools mid-call, and adapts to natural language — unlike IVR systems that use predefined menus. A voice ai agent combines STT, LLM, TTS, orchestration, and telephony into a single real-time pipeline.
What are the five layers of a voice agent stack?
The five voice agent stack components are: STT (converts speech to text), LLM (determines intent and generates responses), TTS (converts responses to audio), orchestration (manages real-time flow and turn-taking), and telephony (connects to phone networks). Each is a distinct component with its own providers, costs, and failure modes.
What is the difference between a cascading pipeline and speech-to-speech voice agent?
A cascading pipeline routes audio through STT → LLM → TTS in sequence. A speech-to-speech (S2S) model handles the full audio-to-audio process in a single model. The cascading pipeline vs realtime voice agent tradeoff: cascading wins on control, telephony compatibility, and compliance; S2S wins on conversational naturalness and latency when audio conditions are ideal. Most production phone deployments use cascading pipelines.
What TTFB should a voice agent target?
Below 300ms TTFB feels human. The voice agent latency breakdown: STT contributes 100–300ms, LLM 150–500ms, TTS 100–300ms, network hops 50–200ms. With streaming and co-located infrastructure, ~360ms total is achievable. Without streaming, TTFB regularly exceeds 1.5s — at which point call abandonment increases. Industry P95 TTFB runs 1.4–1.7s across millions of real calls.
How much does a voice agent cost per minute?
The voice agent cost per minute breakdown: self-assembled Deepgram + GPT-4o + Cartesia + LiveKit + Telnyx runs ~$0.10/min. Managed platforms like Vapi run $0.09–0.35/min. Open-source is 60–80% cheaper above ~10,000 minutes per month — the break-even for anyone deciding how to build a voice agent efficiently at scale.
What is the best STT for voice agents in 2026?
The best stt for voice agents 2026: Deepgram Nova-3 at $0.0077/min is the fastest (sub-300ms) and cheapest — the standard for real-time voice agent architecture. GPT-4o Transcribe is more accurate (8.9% vs 12.8% WER) but 3× more expensive. For phone-based agents, Deepgram's streaming and telephony optimisation give it a consistent production edge.
How do I choose between Vapi, Retell, LiveKit, and Pipecat?
The how to choose a voice agent platform decision: Vapi and Retell suit ai calling agent deployments needing fast launch below 10K min/month. LiveKit suits technical teams above 10K min/month wanting infrastructure control. Pipecat (open-source voice agent framework) suits teams needing maximum pipeline composability. All four require systematic pre-production evaluation — managed platforms handle infrastructure reliability, not conversation reliability.
What should I test in a voice agent before going live?
Test seven things: scenario coverage at ≥90% task completion; STT accuracy across noise and accent profiles; tool call correctness against downstream system state; P95 TTFB under concurrent load; PSTN telephony separately from WebRTC; pipeline regression after every change; and production monitoring baselines before launch. Silent tool call failures and STT error compounding are the failures most likely to pass transcript evaluation undetected.
Related Articles
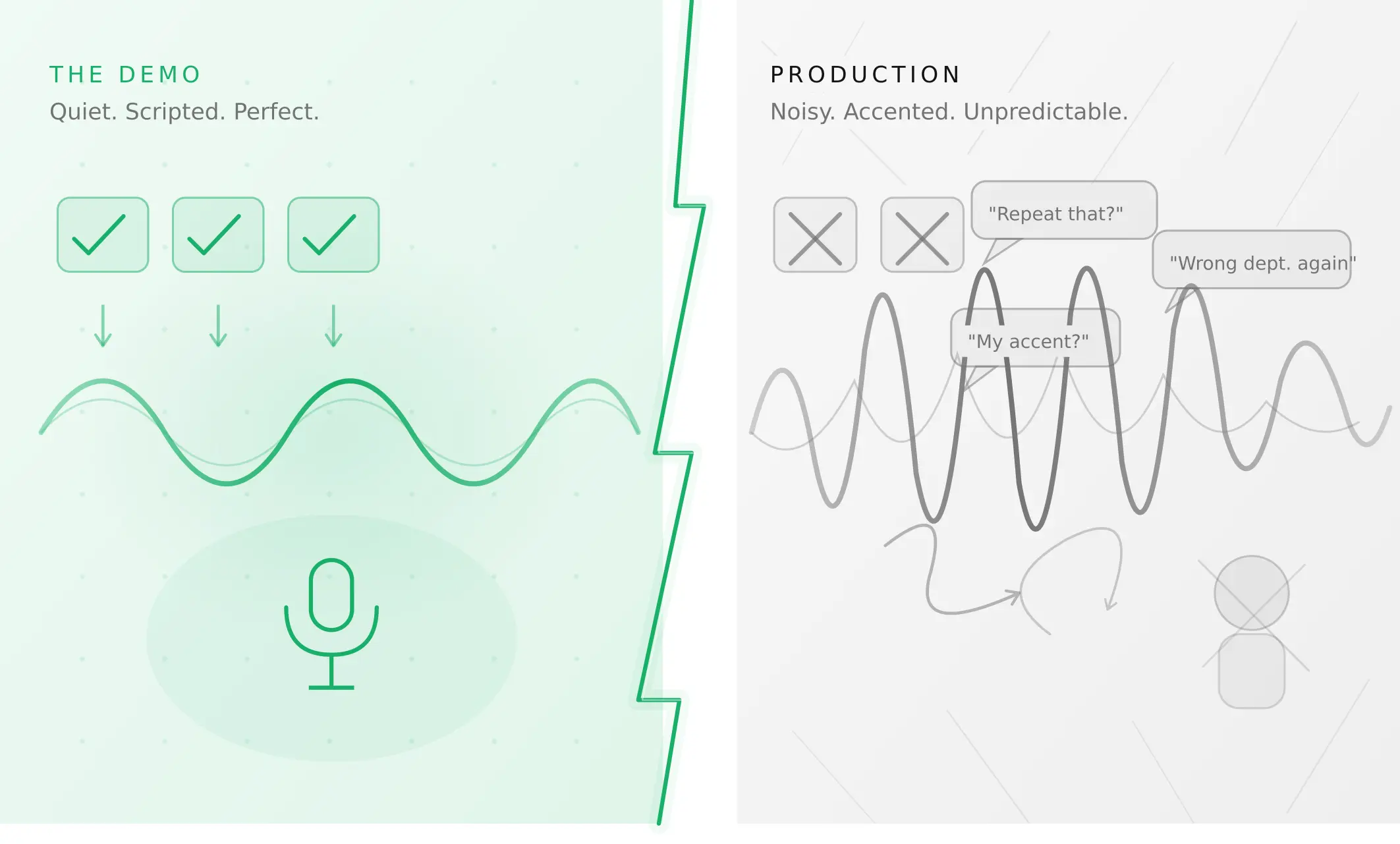
Why AI voice agents fail in production (and how to prevent it)
AI voice agents that ace demos still break in production. Learn the 5 root causes, how to test for each, and what production readiness actually means.
Read more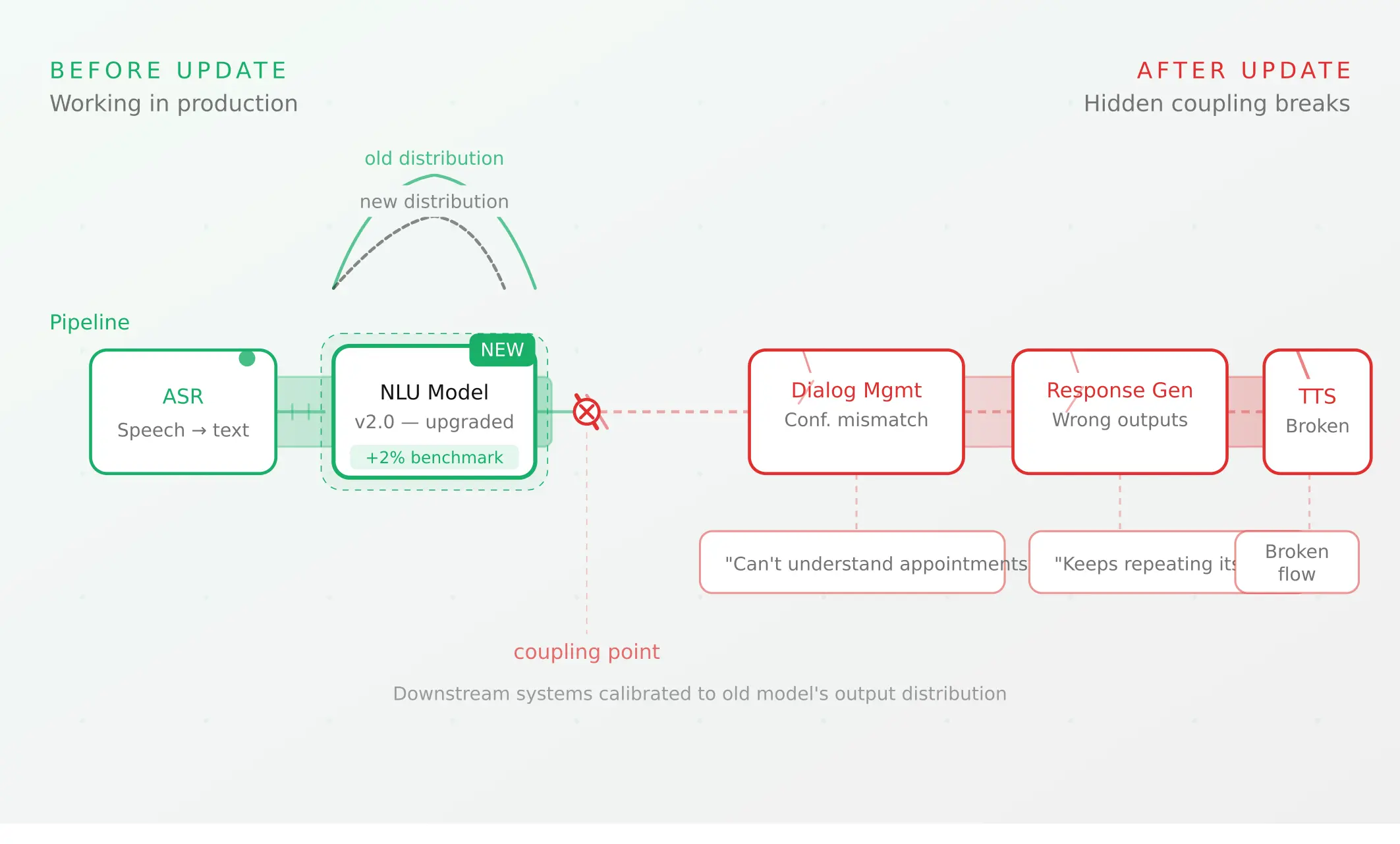
Voice agent regression testing: why LLM updates break production
Updating your LLM improves benchmarks but breaks production voice agents in 5 predictable ways. How to test after every model update and prevent regressions.
Read more