Test your voice agent
Pipecat voice agent testing guide: what to check before going live
It is the open-source Python framework for building real-time voice and multimodal conversational agents. Created by Daily.co — sometimes referred to as pipecat daily — and released under the BSD 2-Clause license, the pipecat ai framework reached v1.0.0, its first production-stable milestone. It is the most widely used real-time orchestration framework for voice AI and the pipecat python package installs in seconds: `pip install pipecat-ai`. Per Pipecat's documentation, it powers agents at companies building customer service, virtual assistants, interactive storytelling, and business automation workflows.
Teams choose it over managed platforms like Vapi or Retell for the same reason they choose any open-source framework: maximum composability. Connect any STT (20+ providers including Deepgram, AssemblyAI, Azure, Google), any LLM (OpenAI, Anthropic, Gemini, Groq, Mistral, Ollama), any TTS (30+ engines including ElevenLabs, Cartesia, Azure, AWS), and any transport (Daily, LiveKit, WebSocket, FastAPI). Every layer is a choice you make and a responsibility you own.
That ownership is the strength and the testing challenge. When you configure the pipeline, you configure every processor — including VAD thresholds, frame routing logic, error handlers, and state machine transitions. A managed platform like Vapi makes these choices for you. Pipecat does not. The failure modes that result from wrong choices are often silent: frames dropped without error, VAD misfires without logs, state transitions that never complete without any exception raised.
This pipecat tutorial covers what to test before your Pipecat pipeline meets real users — and the five failure modes that are specific to how the framework works.
What Pipecat actually is in 2026
This pipecat review covers both the framework and its managed cloud offering.
Pipecat framework is an open-source Python library orchestrating voice agent pipelines. The core concept is the pipeline: a sequence of processors — STT, LLM, TTS, custom frame handlers — through which audio frames flow in real time. It handles the complex orchestration of audio streaming, frame routing, and service integration so you can focus on conversation logic.
Key capabilities at v1.0.0 per Pipecat's GitHub:
- Pipecat Flows — manages complex conversational states and transitions; define structured conversation graphs with explicit state machine logic
- Pipecat Subagents — distributed multi-agent systems where agents communicate through a shared message bus and hand off conversations between specialists
- Built-in VAD — Silero VAD for voice activity detection; configurable thresholds
- Noise cancellation — Krisp Viva, RNNoise, Koala as optional processors
- Transport — WebRTC via Daily or LiveKit, WebSocket, FastAPI, WhatsApp
- Observability — OpenTelemetry and Sentry integrations
- Debug tools — Whisker (real-time pipeline debugger), Tail (terminal dashboard)
Pipecat Cloud is the managed hosting service. It adds: containerised deployment, automatic scaling with unlimited concurrency, multi-region infrastructure, built-in observability, PSTN/SIP telephony, Krisp noise cancellation, and HIPAA/GDPR compliance. Pricing is usage-based — Daily voice minutes are free on Pipecat Cloud; external services (LLM, STT, TTS) are billed directly by those providers.
| Aspect | Pipecat framework | Pipecat Cloud |
|---|---|---|
| Cost | Free (open-source) | Usage-based (Daily minutes free) |
| Infrastructure | Self-managed | Managed, auto-scaling |
| Concurrency | Self-managed | Unlimited |
| Telephony | DIY (Daily/LiveKit/Twilio) | Built-in PSTN/SIP |
| Compliance | DIY | HIPAA/GDPR |
| Observability | OpenTelemetry/Sentry | Built-in monitoring + telemetry |
| Best for | Full infrastructure control | Scale without DevOps overhead |
Pipecat vs LiveKit vs Vapi: choosing the right approach
The pipecat vs livekit which is better 2026 question is the most common comparison in the developer community. The pipecat vs vapi comparison is less technical and more philosophical.
| Dimension | Pipecat | LiveKit Agents | Vapi |
|---|---|---|---|
| Architecture | Pipeline-first | Room-first (WebRTC) | Managed platform |
| Abstraction level | Framework (you own logic) | Framework (you own logic) | Platform (they manage) |
| Pricing | Free + provider costs | $0.01/min + provider costs | $0.05/min + provider costs |
| Concurrency | Self-managed / Cloud unlimited | Self-managed / Cloud tiers | 10 lines PAYG |
| Customisation | Maximum — any processor | High — any provider | Medium — BYOK |
| Turn detection | Silero VAD (configurable) | Semantic + endpointing | Platform-managed |
| Telephony | Daily/LiveKit/DIY | Native SIP (2025) | Twilio/Telnyx |
| Best for | Max composability, pipeline control | Real-time WebRTC, multimodal | Fast deployment, less config |
| Testing challenge | Pipeline frame logic, VAD | Turn detection, worker scaling | Webhooks, prompt sensitivity |
Pipecat is the right choice when: you need maximum control over every processing step, you are building multimodal agents (voice + video + text), you want to compose custom frame processors, or you need an open source voice agent framework without any platform lock-in. For pipecat testing specifically, this means owning the entire evaluation surface — VAD, frames, transport, state machine, and regression.
LiveKit is the right choice when: you need native WebRTC room infrastructure, your agents interact within multi-participant contexts, or you need the LiveKit SIP telephony stack.
Vapi is the right choice when: you need to deploy quickly with minimal infrastructure management, your team's engineering bandwidth is better spent on product than platform.
Five ways Pipecat voice agents fail before they reach users
1. VAD misconfiguration — does the agent know when to listen and when to speak?
Voice Activity Detection is the mechanism for determining when a user is speaking and when they have finished. Pipecat uses Silero VAD by default — a configurable threshold-based model. Getting this configuration right before production is one of the most consequential pre-launch decisions you will make.
The pipecat vad configuration voice agent failure modes are two-sided:
VAD sensitivity too high (low threshold): the agent detects speech where there is only background noise. A user calling from a noisy office triggers VAD on ambient conversation, causing the agent to attempt to process audio that contains no user intent. In streaming pipelines, this sends spurious audio frames through the STT processor, generating garbage transcripts that the LLM must then interpret.
VAD sensitivity too low (high threshold): the agent misses the end of the user's turn. The user finishes speaking, waits for a response, and the agent never registers turn completion because the VAD threshold was set for a quieter environment than production audio. The result is silence — which users interpret as a broken call.
Neither failure produces an exception. Both produce silent conversation breakdowns.
The Evalgent angle: Evalgent's caller profiles configure acoustic conditions independently per synthetic caller — including noise level, speech pace, and disfluency rate. Run your VAD configuration against at minimum three noise profiles (45dB, 65dB, 75dB) before launch. The VAD threshold that works in your development environment may fail consistently in a noisy contact centre or street-traffic background. Document the threshold settings that maintain acceptable turn detection accuracy across your expected acoustic distribution.
# Configuring Silero VAD in Pipecat — key parameters to test
from pipecat.vad.silero import SileroVADAnalyzer
from pipecat.vad.vad_analyzer import VADParams
vad = SileroVADAnalyzer(
params=VADParams(
confidence=0.7, # Test: too low → noise triggers VAD; too high → misses turns
start_secs=0.2, # Test: too short → false starts; too long → cuts off quick speakers
stop_secs=0.8, # Test: too short → agent interrupts; too long → dead air after turn
min_volume=0.6 # Test: too high → quiet speakers get ignored
)
)
# Run this configuration against noise profiles at 45dB, 65dB, 75dB
# before any production deployment2. Pipeline frame processing errors — does every frame make it through?
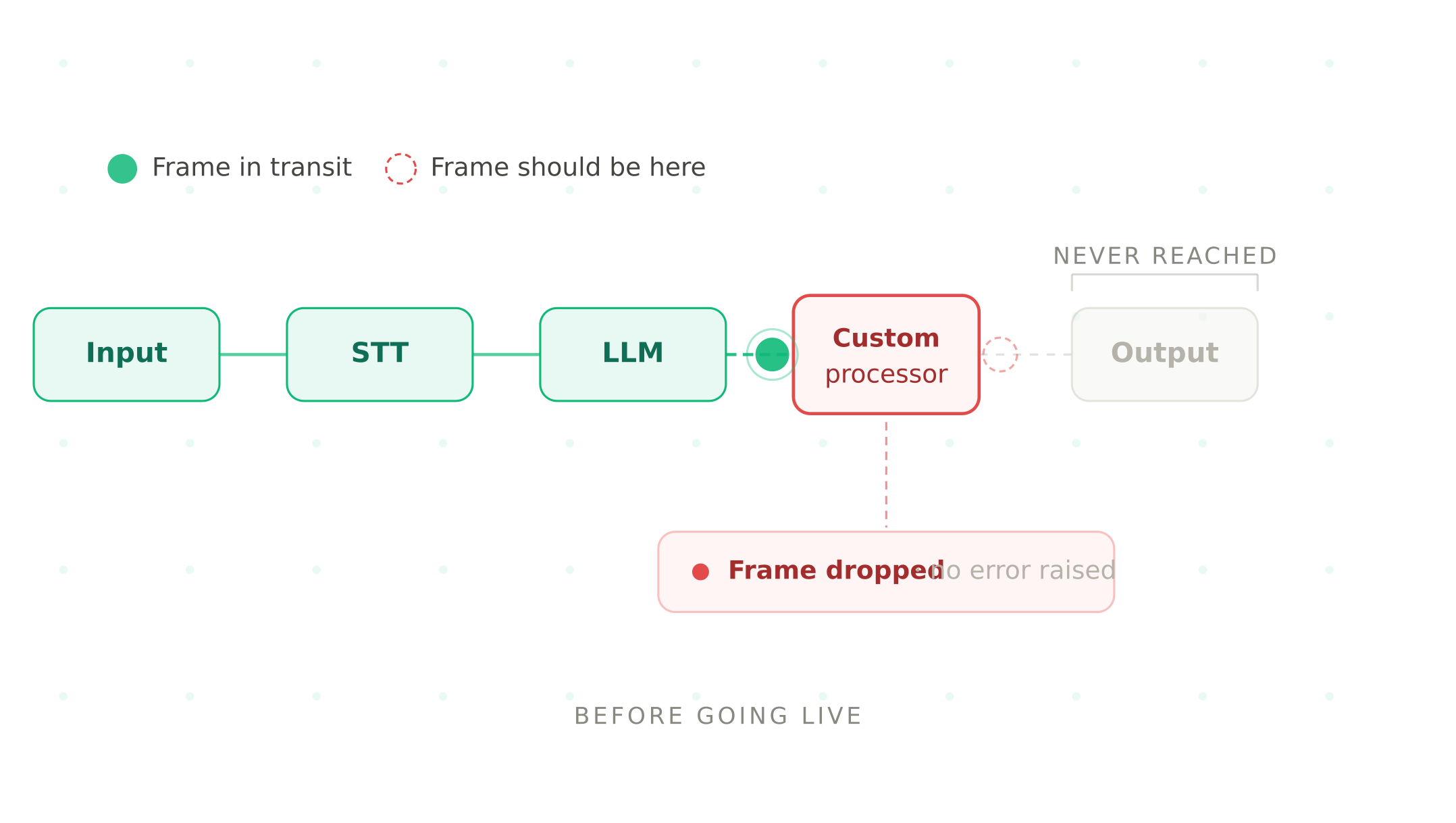
This is the most Pipecat-specific failure mode in the series — there is no equivalent concept in Vapi, Retell, or ElevenLabs.
Pipecat processes conversation data as frames — discrete units of audio, text, and control signals that flow through your pipeline processors in sequence. When a processor fails, the default behaviour depends entirely on how you have configured error handling. Without explicit error handling, a failed processor can drop the frame silently — no exception, no log entry, no user-visible error. The conversation simply becomes less coherent without an obvious cause.
The pipecat pipeline frame errors production scenario most teams discover too late: a custom processor that handles tool call results fails on an unexpected API response format. The frame is dropped. The LLM never receives the tool call result. The agent produces a response that ignores what the tool returned — often confidently incorrect. The conversation transcript looks normal. The error is invisible.
# Pipecat pipeline with explicit error handling for frame processors
from pipecat.pipeline.pipeline import Pipeline
from pipecat.frames.frames import ErrorFrame
class MyToolProcessor(FrameProcessor):
async def process_frame(self, frame, direction):
try:
# Process tool call result
result = await self.call_tool(frame)
await self.push_frame(result)
except Exception as e:
# Without this: frame is silently dropped
# With this: downstream processors receive an ErrorFrame
await self.push_frame(
ErrorFrame(error=f"Tool call failed: {str(e)}")
)
await self.push_frame(frame, direction)Always add explicit error handling to every custom processor. Use `ErrorFrame` to signal failures downstream so the pipeline can respond gracefully rather than silently degrading.
The Evalgent angle: Evalgent's scenario testing runs each scenario end-to-end and verifies outcomes against downstream system state — not just whether a transcript was produced. For Pipecat agents, this means testing every processor failure path explicitly: what happens when a tool call fails? When the LLM returns an unexpected format? When the STT processor produces an empty transcript? Each failure path needs a defined, tested behaviour.
3. Transport and session failures — does the call survive connection issues?
Pipecat's WebRTC transport (via Daily or LiveKit) handles the real-time audio connection between your agent and the user. Transport failures — network interruptions, session drops, WebRTC reconnection — are a production reality that almost no team tests before launch.
The failure pattern: a user's network connection drops for 3 seconds mid-conversation. WebRTC attempts to reconnect. Depending on how you have configured Pipecat's session management, one of three things happens:
1. Best case: the session reconnects, pipeline state is preserved, the conversation continues
2. Common case: the session reconnects but pipeline state is lost — the agent has no memory of the conversation so far and greets the user again
3. Worst case: the session fails to reconnect and the call drops silently — no goodbye, no escalation, just dead air
None of these behaviours are determined by Pipecat defaults. They are determined by how you configure session management and reconnection logic. And almost no team tests this before launch because it requires simulating network interruption at the transport layer — something manual testing cannot do reliably.
Cloud handles much of this at the infrastructure layer: containerised deployments with stateful connections and multi-region availability. For self-hosted deployments, reconnection handling is entirely your responsibility.
The Evalgent angle: Synthetic caller testing at concurrent load reveals transport pressure — multiple simultaneous sessions sharing infrastructure reveal capacity and connection stability issues that single-session testing never surfaces. For Pipecat Cloud deployments, test at 2× expected peak concurrent sessions. For self-hosted deployments, add explicit network interruption tests to your pre-launch checklist.
4. Pipecat Flows state machine correctness — does every conversation path complete?
Pipecat Flows manages complex conversational states and transitions — defining structured conversation graphs with explicit nodes for each stage of the interaction. A booking flow might have nodes for intent capture, date selection, time selection, confirmation, and completion. Each node has defined transitions based on user input or system events.
The pipecat flows testing conversational state failure mode is path coverage. Teams test the happy path — the cooperative user's sequence of states. They do not test the full state space: what happens when a user skips a required node? When the transition condition is ambiguous? When the system event triggering a transition never fires?
A state machine with 5 nodes and 3 possible transitions per node has up to 243 paths. Manual testing with 10 conversations covers less than 5% of them. The failures live in the untested 95%.
The Evalgent angle: Evalgent's scenario library defines each conversation flow with explicit success criteria — the expected final state, the expected tool calls, the expected outcomes. For Pipecat Flows agents, each defined path in the state machine becomes a testable scenario. Run the full scenario suite against your state machine before launch. Any path that is unreachable in testing will be reachable in production — and will produce undefined behaviour.
5. Pipeline regression after processor changes — does it still work after the last commit?
Pipecat agents are code. Every commit is a regression risk — not just of the processor you changed, but of everything downstream from it.
In managed platforms like Vapi or Retell, a configuration change affects one layer. In Pipecat, a change to any processor affects the frame types and content that downstream processors receive. A change to the STT processor changes what the LLM receives. A change to the LLM changes what the TTS speaks. A change to a custom frame processor between LLM and TTS can silently modify the spoken response.
For teams using Pipecat Subagents, the regression surface expands further. A change to one subagent's message format can break another subagent's handler without any direct code dependency.
The Evalgent angle: Regression testing with a golden scenario suite — required to pass before any commit reaches production — makes Pipecat safe to change at scale. Define your baseline against a known-good commit. Any degradation in task completion rate, turn-taking accuracy, or tool call correctness flags a regression before users experience it.
Pipecat vs LiveKit: the pipeline vs room distinction
The architectural difference between Pipecat and LiveKit clarifies what you are testing in each.
Pipecat is pipeline-first. Your agent IS a pipeline — a sequence of processors through which frames flow. It is decoupled from any specific transport. You can run the same pipeline over WebRTC, WebSocket, or any other transport. The testing challenge: you own the frame processing logic, error handling, and state management.
LiveKit is room-first. Your agent is a participant in a WebRTC room. The testing challenge: you own the worker process scaling, turn detection configuration, and room state management.
Choose Pipecat when: you need maximum pipeline composability, you want to run the same agent logic across multiple transport types, or you are building voice + video multimodal agents where the frame architecture handles mixed media naturally.
Choose LiveKit when: you need native WebRTC room infrastructure, your agents interact with multiple participants simultaneously, or you need the LiveKit SIP telephony stack.
Pre-launch testing checklist for Pipecat voice agents
This is the definitive guide on how to test a pipecat voice agent before deployment. Complete every step before any voice agent built on Pipecat goes live:
1. Verify pipeline connectivity — run a complete pipeline end-to-end with your chosen STT, LLM, and TTS providers. Verify frames flow correctly from input to output with a simple test utterance.
2. Calibrate VAD thresholds — run your Silero VAD configuration against noise profiles at 45dB, 65dB, and 75dB. Document threshold settings that maintain turn detection accuracy across your expected acoustic environment. Adjust before launch, not after.
3. Test all processor error paths — for every custom processor, test what happens when the downstream service returns an error, times out, or returns an unexpected format. Verify explicit ErrorFrame handling rather than silent frame drops.
4. Run full scenario suite — every designed conversation flow, end-to-end. Flag any scenario with task completion below 90%.
5. Test Flows state machine — if using Pipecat Flows, enumerate every transition path and test each one explicitly. Every defined state must be reachable and produce the expected outcome.
6. Test transport resilience — simulate network interruption mid-conversation and verify session state behaviour. For Cloud deployments, test at 2× expected peak concurrent sessions. For self-hosted, test reconnection logic and state recovery explicitly.
7. Verify tool call outcomes against system state — for every tool call your agent can make, verify the downstream system received the correct request. This is the only reliable method for catching tool call failures that look like successes in transcript evaluation.
8. Run regression suite after final commit — do not deploy from an actively edited branch. Deploy from the commit whose full scenario suite has passed against your baseline.
Monitoring Pipecat agents in production
Once live, these metrics reveal Pipecat-specific production health:
VAD false positive rate. Track how often the VAD triggers without a user utterance following. A rising false positive rate signals that acoustic conditions in production differ from your test calibration.
Frame processing error rate. Monitor ErrorFrame occurrences in your pipeline. Any ErrorFrame reaching the end without handling is a silent conversation failure. Set alerts on ErrorFrame count per hour.
Flows state completion rate. If using Flows, track the percentage of conversations reaching a terminal state versus those stranded in intermediate states. A rising stall rate signals a state machine path not completing under real user behaviour.
Pipeline P95 latency by processor. With OpenTelemetry integration, frame latency traces through each processor. Monitor P95 per processor — a spike in one is invisible in aggregate TTFB but immediately affects conversation quality for affected calls.
Use Evalgent's production monitoring to correlate these Pipecat pipeline signals with end-to-end task completion outcomes.
Summary
Pipecat is the leading open-source Python framework for voice AI at v1.0.0. Test five things: VAD calibration, frame error handling, transport resilience, Flows state machine, and regression.
Frequently asked questions
What is Pipecat and who built it?
An open-source Python framework (BSD 2-Clause) for real-time voice and multimodal conversational agents, created by Daily.co. At v1.0.0, it supports 20+ STT providers, 30+ TTS engines, and transports including WebRTC via Daily or LiveKit. Its pipeline architecture connects processors — STT, LLM, TTS, custom handlers — through which audio frames flow in real time.
What is the difference between Pipecat framework and Pipecat Cloud?
The framework is free, open-source, and self-managed — you run your pipeline on your own infrastructure. Pipecat Cloud is a managed hosting service: containerised deployment, auto-scaling, unlimited concurrency, built-in PSTN/SIP telephony, monitoring, and HIPAA/GDPR compliance. The pipecat cloud vs self hosted decision is primarily infrastructure overhead versus cost control at scale.
How does Pipecat compare to LiveKit for voice agents?
The framework is pipeline-first — your agent is a processor chain that frames flow through. LiveKit is room-first — your agent is a participant in a WebRTC room. Both are open-source with similar cost structures. The pipecat vs livekit which is better 2026 answer: choose Pipecat for maximum pipeline composability and multimodal agents; choose LiveKit for native WebRTC rooms and multi-participant interactions.
What is Pipecat VAD and how do I configure it?
Silero VAD handles voice activity detection with four configurable parameters: confidence threshold, start_secs, stop_secs, and min_volume. The pipecat vad configuration voice agent challenge is that the right threshold depends on your acoustic environment. VAD too sensitive → noise triggers false detections. VAD too conservative → agent misses turn completions. Test all four parameters against your expected noise profiles before launch.
What is Pipecat Flows and how do I test it?
Flows manages complex conversational states and transitions — structured conversation graphs where each node represents a stage with explicit transition conditions. The pipecat flows testing conversational state requirement: enumerate every path through your state machine and test each one. Happy-path testing covers a small fraction of the total path space. Unreachable paths in testing will be reachable in production.
What breaks in Pipecat voice agents in production?
The most common pipecat pipeline frame errors production failures are: VAD thresholds miscalibrated for real acoustic conditions; custom processors dropping frames silently on errors instead of raising ErrorFrame; WebRTC session drops losing pipeline state; Flows transitions stalling when user input does not match expected patterns; and pipeline regressions where a processor change breaks downstream frame handling.
How does Pipecat handle multi-agent workflows?
Subagents enables distributed multi-agent systems where each agent runs its own pipeline and communicates through a shared message bus. Agents hand off conversations between specialists and dispatch background tasks. Testing requirement: verify message format compatibility between subagents. A change to one subagent's output message format can break another subagent's handler without any direct code dependency.
How do I test a Pipecat voice agent before going live?
This pipecat testing guide summarises the eight-step pipecat voice agent testing guide: verify pipeline connectivity; calibrate VAD across noise profiles; test all processor error paths with ErrorFrame handling; run your full scenario suite; test all Flows state machine paths; test transport resilience; verify tool call outcomes against downstream system state; and run your regression suite before every deployment.
Related Articles
Conversational AI testing: the complete voice agent stress testing guide
Systematic conversational ai testing for voice agents. Find breaking points across noise, accents, interruptions, and latency before real users do.
Read more
ElevenLabs voice agent testing guide: what to check before going live
Test your ElevenLabs voice agent before going live. Covers scenario gaps, user behaviour, tool calls, concurrent limits, and voice quality regression.
Read more