Test your voice agent
Why Production Voice Agents Are Becoming Graphs, Not Prompts
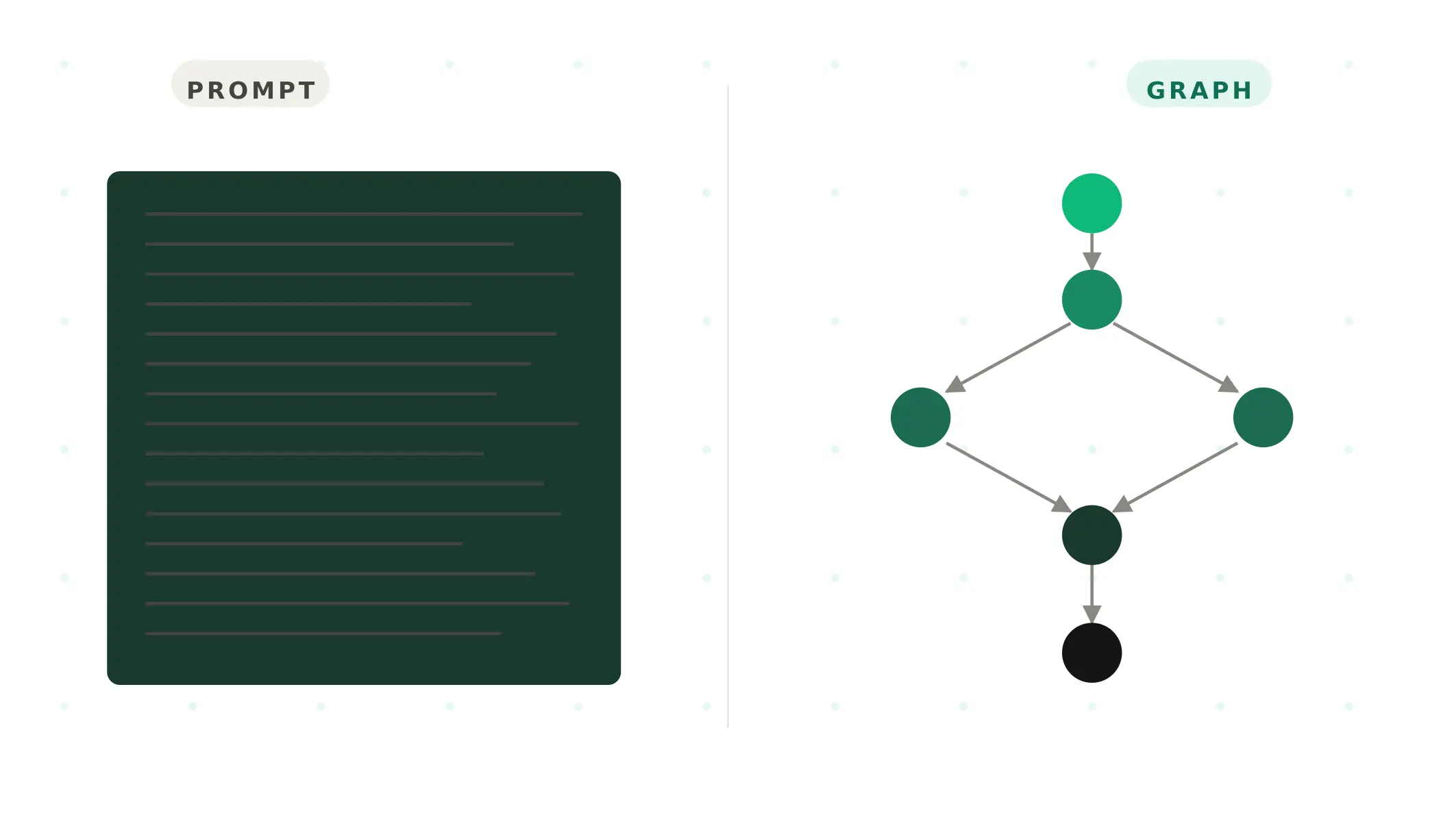
Two years ago, almost every voice agent was prompt-based. One LLM, one 4,000-word system prompt, the whole behaviour spec packed into instructions and hope. Demos were impressive. Production deployments mostly were not. In 2024, teams shipping ai voice agents at scale stopped writing longer prompts and started writing graphs. By 2026, most production voice deployments — on a voice ai platform, voice ai tool, ai voice bot, or self-built voice ai bot — are graph-based, hybrid, or actively migrating. The reasoning is not about LLMs getting worse. Teams realised the LLM works better as a component than as the system.
This post explains what a graph based voice agent actually is, why the prompt based voice agent fails at production scale, and where graph-based wins. By the end you should be able to look at any voice agent codebase — any ai voice call automation, agents of ai handling structured workflows, or ai voice tool integrating into a contact centre — and tell which architecture it is built around.
What a graph based voice agent actually looks like
Take a concrete case. A bank wants a voice agent that handles inbound calls about appointment booking — schedule, reschedule, cancel, check availability. A prompt based agent puts all that logic into one system prompt. Roughly four thousand words describing every flow, every edge case, every fallback, every tone requirement, every tool, every escalation condition. The team ships that prompt to GPT-4o, hooks it up to a STT-LLM-TTS pipeline, and the agent works for the demo.
The same agent built as a graph looks completely different. There is a `START` node connected to `Greet` and then `Identify caller intent`. That intent node is a focused LLM call with a short prompt and structured output. It classifies the caller's request into one of four enum values and routes to the corresponding subgraph. The `Schedule appointment` subgraph has its own nodes: `Capture appointment type`, `Check availability` (deterministic tool call, no LLM), `Propose slots`, `Confirm selection`, `Send confirmation` (tool node), `END`. Each edge has a condition. Each LLM-driven node has a focused 50–200 word prompt with a strict output schema.
The visual difference is everything. The prompt-based agent's logic is implicit. It lives inside the LLM's attention over a 4,000-word string. The graph-based agent's logic is explicit. Every transition, every condition, every tool call is a line of code that can be read, tested, and changed in isolation. This is what good graph based agent design looks like in practice — and where the graph based vs prompt based voice agent comparison really lands. The LLM is used for what LLMs are good at. Everything else is deterministic. Strong voice agent state graph design treats LLM nodes as expensive function calls — used precisely, audited regularly, swapped easily.
Why prompt based voice agent architectures fail at production scale
The reason teams move off prompt based voice agent architectures is not philosophical. It is empirical. Prompt-based agents fail in four specific ways under production load, each harder to fix than the last.
Prompt drift across turns. A long system prompt is loaded at the start of every turn. The LLM is supposed to follow it across an entire multi-turn conversation. In practice, by turn six or seven, the model has subtly disagreed with the prompt's intent on one or two instructions. The agent uses a tone the prompt forbade. The agent skips a step the prompt required. The agent calls a tool with arguments the prompt specified differently. No single deviation is dramatic. The cumulative effect is that the agent works one way at turn one and a slightly different way at turn ten. The team cannot tell why without reading transcripts.
Invisible regression. Change one sentence in the prompt to clarify some edge case. Ten downstream behaviours change. The team might not notice for weeks. There is no way to verify that fixing failure mode A did not introduce failure mode B, except by running the entire scenario suite again. Most teams do not. Prompt drift compounds with prompt regression, and the agent's behaviour becomes effectively unpredictable across releases.
Implicit control flow. Debugging "why did the agent ask for the customer's policy number twice" means rereading 4,000 words and guessing where the LLM lost the thread. There is no execution trace. There is no log line saying "entered state X, transitioned to state Y, called tool Z." Just a transcript and the prompt. The team reasons backward from failure to instruction. This works for some failures. It does not scale.
Unreliable tool calling. The LLM decides when to call which tool, in what order, with what arguments. It is right most of the time. Most of the time is what kills voice agents in production. A 5% tool-call error rate looks fine in evaluation. It means one in twenty appointments are booked at the wrong time, one in twenty payments are processed for the wrong amount, one in twenty escalations go to the wrong queue. These errors are the most expensive failures voice agents produce. Prompt-based architectures cannot prevent them — only hope to minimise them.
These failure modes are documented in why voice agents fail in production. This is why voice agents need graph architecture: a longer prompt does not fix any of the four failure modes above. A different architecture does.
Why graph based agent design emerged
Graph based agent design emerged because the alternative stopped scaling. The shift happened across roughly twenty-four months, driven by three converging forces.
The first was LangGraph. LangChain released LangGraph in early 2024 as the first widely-adopted execution-graph framework for LLM agents. The framework let teams encode agent behaviour as a state graph — nodes for LLM calls and tool calls, edges for routing, explicit state passed between nodes. It was not voice-specific, but it solved the structural problem at the LLM-application layer. The voice teams picked it up quickly. A LangGraph voice agent architecture became the default pattern for serious builders. By mid-2024, voice-specific graph frameworks started appearing. Pipecat Flows from Daily, voice-native and built on Pipecat's pipeline framework. The first true Pipecat Flows voice agent deployments shipped to production within months. Vapi Workflows, managed and visual. Retell Conversation Flows, similar idea, different abstractions. By 2026, every serious voice-agent platform either ships a graph-based abstraction or has one on its roadmap.
The second was the broader agentic architecture shift. Anthropic's Building Effective Agents essay made the structural argument explicit. Effective AI agents are workflows of LLM calls connected by deterministic logic, not autonomous loops of one LLM trying to do everything. OpenAI's structured outputs and function-calling improvements pushed in the same direction. Model Context Protocol formalised how agents call tools. The whole ecosystem was telling builders the same thing: externalised logic beats implicit logic.
The third was production failure data. Teams that shipped prompt based voice agent systems in 2023 had eighteen months of evidence by 2025 that the architecture was not working at scale. Gartner now predicts that over 40% of agentic AI projects will be cancelled by 2027 due to escalating costs, unclear business value, and inadequate risk controls. The post-mortems consistently point to the same architectural mistake: trusting the LLM to manage control flow it was never designed to manage. Teams that had moved to graph-based architectures shipped more reliably, debugged faster, and operated at higher scale on the same model budget. The pattern was clear enough by late 2024 that new voice-agent projects defaulted to graph.
What goes inside each node — the LLM's actual job
A common misreading of graph based agent design is that it removes the LLM. It does not. It puts the LLM in the right place. Graph-based voice agents call LLMs constantly — they just call them differently. Each LLM-driven node has three characteristics that determine its reliability.
The first is a short, focused prompt. Where a prompt-based agent's system prompt runs 4,000 words, a node-level prompt runs 50–200. It does one thing. "Classify this user message into one of these four intents." "Extract the appointment date, time, and provider from this utterance." "Generate a polite response confirming the user's selection." Short prompts are dramatically more reliable than long ones. The LLM does not have to remember and reconcile ten different requirements simultaneously.
The second is a specific output schema. Each node specifies exactly what shape its output should take — usually a JSON schema enforced by structured-output APIs, or a pydantic model in code. The LLM does not free-form text into the next node. It produces structured data the next node can consume deterministically. This eliminates failures where the LLM's output is interpretable to a human but not parseable by code.
The third is no cross-turn memory inside the node. The graph holds the conversation state. The node does not. When the `Capture appointment type` node runs, it sees only what it needs — the current user message and any relevant prior state the graph passes in. Not the entire conversation history. Node behaviour becomes much more predictable. The LLM is not trying to weigh signals from twelve turns ago against the current request.
These three properties — short prompt, structured output, no implicit memory — are why graph-based agents get their reliability dividend. A 50-word prompt with a JSON schema is closer to a reliable function call than to a free-form LLM completion. It will not be perfect. It will be measurably more consistent than a single long system prompt.
The five categories of nodes in a typical voice agent graph
Most production voice-agent graphs use a small set of recurring node types. Recognising them is the fastest way to read a graph based agent design and understand what it is doing.
Intent classification nodes route the conversation. They take user input and produce a categorical decision — which subgraph runs next. These are short LLM calls with enum outputs. They are the most LLM-suitable nodes because classifying meaning is what LLMs are best at.
Information extraction nodes pull structured data out of natural language. The user says "I'd like to come in next Tuesday afternoon" and the extraction node returns `{date: "2026-05-26", time_range: "afternoon"}`. These are LLM calls, short, structured-output enforced. They convert unstructured input into structure the rest of the graph can act on.
Tool execution nodes call external systems — database lookups, API calls, calendar reads, CRM writes. These are pure code, no LLM involved. The graph routes execution to the tool node, the tool runs, the result is added to the conversation state, the graph continues. Failure modes are normal software failure modes — timeouts, error codes, rate limits — not LLM failure modes.
Response generation nodes produce natural-language output to send back to the user. Given structured state ("appointment confirmed for May 26 at 2pm with Dr. Chen"), the response node generates a polite confirmation. These are LLM calls with prompts focused entirely on tone, brevity, and naturalness — not on logic.
Conditional routing nodes are pure code with no LLM. They evaluate state — "if appointment_type == 'urgent', route to escalation; else route to standard_booking" — and choose the next node. They handle the deterministic branching that prompt-based agents would have asked the LLM to handle.
Real voice-agent graphs are mixtures of these five, with proportions depending on the use case. A booking agent might be 30% intent classification, 25% tool execution, 20% extraction, 15% response generation, 10% conditional routing. A diagnostic agent leans more on intent and extraction. The taxonomy is not deep — but most teams will not have it explicit yet, and naming the categories makes the architecture conversation faster.
Where graph based architectures trade off
Graph based voice agent architectures are not free. Three trade-offs are real and worth being honest about.
Longer to build. A prompt-based voice agent MVP takes a weekend. Write a good prompt, hook up STT-LLM-TTS, ship. A graph-based MVP takes a sprint. The conversation flow has to be designed before code is written. The state schema has to be defined. The nodes have to be implemented and connected. The wins come later, in maintenance and scaling. Teams that just want to validate an idea quickly may rationally start prompt-based and migrate later.
More upfront design work. Prompt-based architectures let you describe what you want the agent to do in prose. Graph-based architectures force you to design the conversation as a state machine. This is mostly a feature — it surfaces ambiguities early — but it is also a cost. Product managers who can write a prompt cannot always design a graph. The cognitive load of explicit state design is higher than the cognitive load of writing instructions.
Some conversations do not fit a graph. Open-ended advisory conversations — financial planning, complex medical triage, exploratory product discovery — genuinely benefit from the LLM's flexibility across long, unpredictable conversations. Over-constraining these with a tight graph hurts more than it helps. The architectural pattern that fits is hybrid: a graph backbone for the parts where structure matters (intent routing, tool calls, compliance checks), with prompt-heavy nodes for the parts where flexibility matters. Most production voice agents that handle anything non-transactional end up hybrid.
The position this post takes is specific: for transactional voice agents — appointment booking, customer support, sales qualification, account management, payment processing — graph based agent design wins. That covers the bulk of production voice AI being shipped right now. For genuinely advisory agents, hybrid is the right pattern. For tiny MVPs, prompt-based is defensible. When to use graph based voice agent architecture depends on what the agent has to do.
Production frameworks worth knowing
Several frameworks ship graph-based abstractions for voice agents. Each takes a different position on flexibility versus ease-of-use.
LangGraph is the most flexible and most widely-adopted. General-purpose, code-first, integrates with any LLM or tool. Requires the team to write more code than visual platforms, but produces the most controllable systems. Strong for teams that want to own their stack.
Pipecat Flows is voice-native, built on top of Pipecat's pipeline framework. It handles voice-specific concerns — turn detection, interruption handling, audio buffering — natively, where LangGraph treats voice as an integration concern. See Pipecat-based voice agent guidance for more.
Vapi Workflows is managed, visual, hosted. Drag-and-drop graph editor. Faster to ship, less control. Strong for teams that want graph architecture without operating the infrastructure.
Retell Conversation Flows is similar in spirit to Vapi — managed graph-based agent builder, different specific abstractions, different pricing model.
Self-built state machines are what teams do when they outgrow off-the-shelf frameworks. Custom code, custom abstractions, fully owned. The trajectory for any voice-agent team that scales far enough usually ends here.
The choice between these is mostly about how much of the agent stack the team wants to own. None of them changes the underlying architectural argument: graph-based voice agents work because they externalise control flow. The framework is the implementation detail.
Testing graph based voice agents
Graph based voice agent testing is more tractable than testing a prompt-based agent, but only at the right level. The temptation is to write unit tests for each node, confirm they pass, and assume the agent works. That misses what voice agents actually fail on.
Three test tiers matter. Node-level tests verify each LLM node in isolation — does the intent classifier correctly classify representative user messages, does the extraction node return the right structured data. These are fast, cheap, and belong in CI. Subgraph tests verify that a flow completes end-to-end with the right tool calls in the right order, given a synthetic caller — including correct fallback handling when the user goes off-script. Medium cost, runs on every merge. End-to-end voice tests put the entire agent through real acoustic conditions with synthetic callers, real telephony, real latency, with attention to conditional edges and node-based architecture transitions under stress. Full scenario × profile matrix.
Most teams stop at node-level. They should not. Graph architecture solves the control-flow problem, but it does not solve the voice problem. A correct graph can still produce an agent that fails in production because of latency cliffs, accent diversity, interruption handling, or unexpected caller behaviour. The same evaluation discipline that applies to prompt-based architecture applies to graph-based — the architecture changes, the voice-specific failure surface does not. For the full methodology, see eval-driven development and ai agent testing vs voice agent testing. A dedicated post on graph-specific testing is forthcoming.
When graph based isn't the right answer
Graph-based architecture is the right call for most production voice agents but not all. Three cases where prompt-based remains defensible:
Tiny MVPs and rapid prototypes. When the goal is to prove an idea works at all, the engineering overhead of designing a graph is friction. Ship a prompt-based agent, validate the use case, migrate to graph when you commit to scaling. The cost of throwing away a prompt-based prototype is a weekend. The cost of throwing away a graph-based prototype is a sprint.
Genuinely open-ended advisory conversations. When the conversation cannot be mapped to a finite set of states — therapy, complex diagnostic conversations, financial planning that goes wherever the client takes it — over-constraining with a graph hurts. The LLM's flexibility across long, unpredictable contexts is the feature.
Heavy multi-turn reasoning. When the agent genuinely needs the full conversation history to make every decision — and externalising that into graph state would require thousands of state variables — the implicit memory of a long-context LLM is sometimes simpler than the explicit memory of a graph. This is a small minority of use cases.
The argument is not "graph always." It is "graph for the production transactional case, which is most of what is being built." A reader whose use case genuinely sits in one of these exceptions should know that.
Summary
Graph based voice agent architectures externalise the control flow that prompt based voice agent architectures trust the LLM to handle. Production reliability comes from putting the LLM where it belongs — inside small focused nodes, not in charge of everything.
Frequently asked questions
What is a graph based voice agent?
A graph based voice agent encodes its behaviour as a directed graph of nodes and edges. Each node handles a specific task — intent classification, information extraction, tool calls, response generation. The LLM is used inside specific nodes for what LLMs are good at, while deterministic routing handles the control flow between them.
How is graph based different from prompt based agent design?
Prompt based agent design puts all behaviour into one long system prompt and trusts the LLM to follow it. Graph based agent design externalises the logic into explicit nodes and transitions. The LLM gets short focused prompts at specific decision points. Control flow lives in code, not the LLM's attention.
Why are production voice agents moving to graph based agents?
Production voice agents move to graph based agents because prompt based voice agent architectures fail at scale. Long prompts drift across turns. Regressions become invisible. Control flow cannot be debugged. Tool calls become unreliable. Graph based agent design solves all four by making behaviour explicit, testable, and bounded.
What goes inside each node of a graph based voice agent?
Each LLM-driven node in a graph based voice agent has three properties: a short focused prompt (50–200 words), a strict output schema (typically structured JSON), and no implicit memory across turns. The graph holds the state; the node does one thing well. This produces dramatically more reliable behaviour than a single long system prompt.
What are the trade-offs of graph based agent design?
Graph based agent design takes longer to build than a prompt-based MVP — a sprint versus a weekend. It requires upfront conversation design that prompt-based architectures defer. Some conversations — open-ended advisory dialogue, heavy multi-turn reasoning — do not fit cleanly into a graph and benefit from prompt-based or hybrid architectures instead.
Which frameworks support graph based voice agents?
LangGraph is the most flexible and widely-adopted general-purpose framework. Pipecat Flows is voice-native and handles voice-specific concerns. Vapi Workflows and Retell Conversation Flows are managed visual platforms. Teams that scale far enough often end up with custom state machines. Each takes a different position on flexibility versus ease-of-use.
How do you test a graph based voice agent?
A graph based voice agent is tested at three levels. Node-level tests verify each LLM node in isolation. Subgraph tests verify end-to-end flow completion with synthetic callers. End-to-end voice tests put the agent through real acoustic conditions, telephony, and interruption handling. Most teams stop at node-level and miss the production failures.
When should you not use graph based architecture?
Graph based architecture is not the right answer for tiny MVPs where the goal is to validate an idea quickly, for genuinely open-ended advisory conversations that cannot be mapped to a finite state graph, or for agents needing heavy multi-turn reasoning where externalising state would be more complex than letting the LLM handle context implicitly.
Related Articles

How to automate voice agent testing: synthetic callers vs manual QA
Learn how ai test automation replaces manual QA for voice agents. Compare synthetic callers vs human testers, with a 5-step framework to scale without hiring.
Read more
AI Agent Testing vs Voice Agent Testing: What General Tools Miss for Voice
AI agent testing measures text outputs. Voice agent testing measures behaviour through an acoustic pipeline. Five failure categories general tools miss.
Read more