Test your voice agent
Testing Graph-Based Voice Agents: The Three-Tier Model
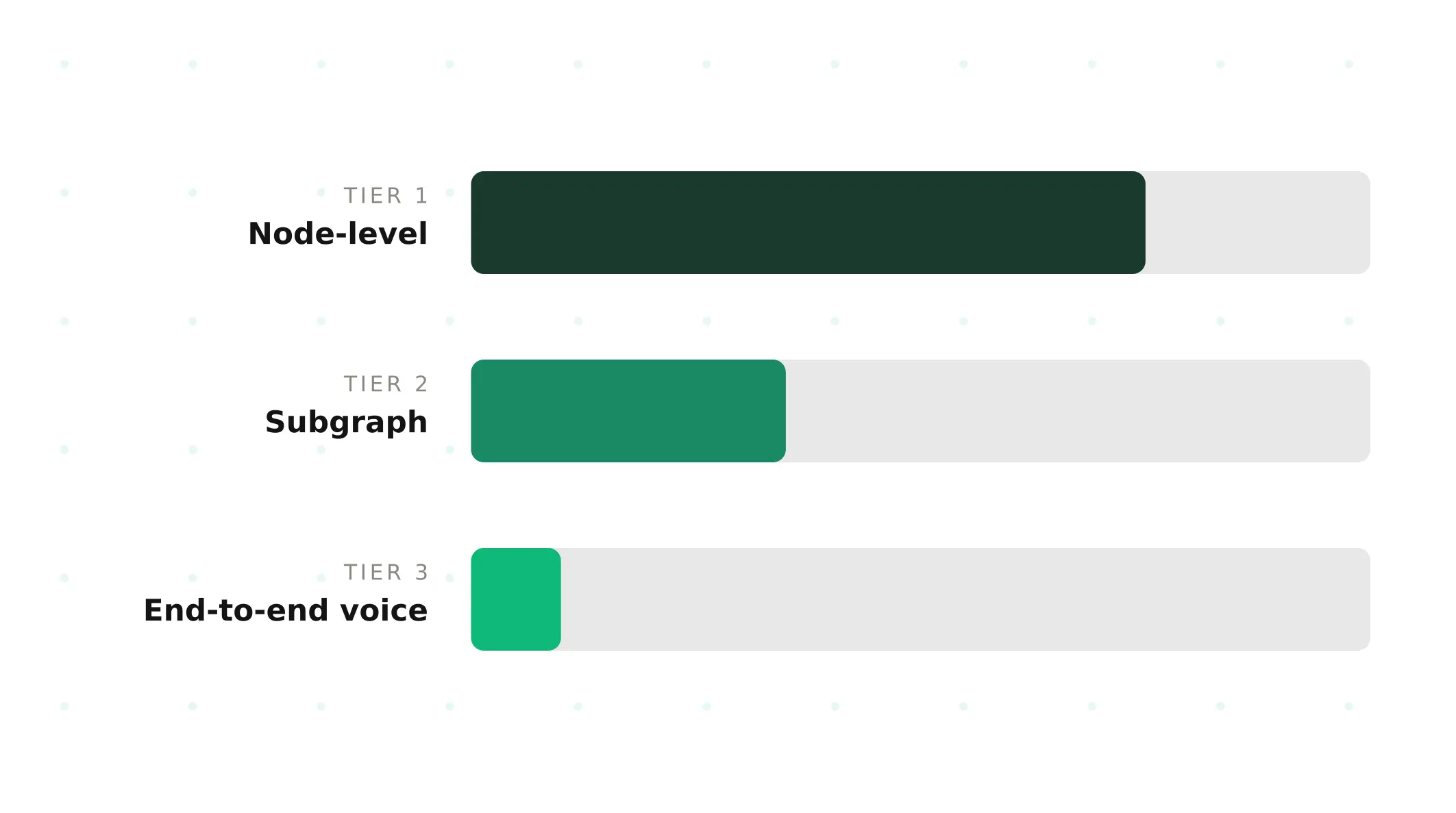
The architectural shift to graph-based voice agents documented in graph-based voice agents — S8 in this series — created a real opportunity that most teams are wasting. Graph-based ai voice agents are far more testable than their prompt-based predecessors. Discrete nodes, explicit state transitions, and bounded LLM calls all open clean test surfaces that did not exist when behaviour lived inside a 4,000-word system prompt. Most teams ship graph-based voice agent implementations having tested only the easiest of the three tiers that matter. They run an ai test pass at the node level, see green checkmarks, and ship.
This post is the methodology — a graph based voice agent testing framework that defines all three tiers. It covers what each tier verifies, what each tier misses, and what production-grade ai evaluation looks like when you do all three. It applies whether you built your agent on LangGraph, Pipecat Flows, Vapi Workflows, Retell Conversation Flows, or a custom state machine. Testing langgraph voice agent implementations and testing Pipecat Flows implementations follow the same methodology. The framework is platform-agnostic; the discipline is what matters.
Why graph-based agents test differently
Teams coming from prompt-based voice agent testing or general ai testing have to unlearn some habits. A prompt-based agent has one testable surface — the conversation. Everything else lives inside the LLM's attention over a long system prompt, and the only way to verify behaviour is to listen to enough calls and hope. A graph based voice agent has multiple testable surfaces. Each node is testable in isolation. Each subgraph is testable as a flow with explicit state transition logic and conditional edge handling. The whole agent is testable end-to-end against real voice conditions. The deterministic routing between nodes can be verified independently of the LLM calls inside them. This is a feature, not a complication.
The catch is that the multiplicity creates a temptation to treat the easiest tier as sufficient. Testing graph based voice agent components at the node level is fast, cheap, and produces green checkmarks in CI. It also misses every failure mode that depends on multiple nodes interacting, on tool calls under load, on acoustic stress, or on caller behaviour that deviates from the test inputs. The production readiness graph based voice agent teams actually need depends on catching the tier 2 and tier 3 failures that the easy tests cannot reach. Teams that ship reliably treat all three tiers as load-bearing parts of the release workflow.
The graph based agent design opportunity is structural. The discipline question is whether the team uses it. Most do not — yet. This post is for the teams that want to.
Tier 1: Node-level testing
Node-level testing is the lowest-cost tier and the easiest to set up. Each LLM-driven node is tested in isolation against a representative input dataset. Pure code nodes (tool calls, conditional routing) get standard unit tests. The tier resembles the unit-testing layer engineers know from non-AI software.
Three categories of LLM-driven node need node-level testing.
Intent classification nodes take user input and produce a categorical decision routing the conversation. Node-level tests for intent classification verify the classifier produces the right enum value for representative user messages. The test set covers the common cases (clear intent), the ambiguous cases (overlapping intent), and the edge cases (off-topic, escalation, silence). Pass/fail is binary: did the structured output match the expected enum?
Information extraction nodes pull structured data out of natural language. Node-level extraction tests verify the extractor returns the right JSON for representative utterances. "I'd like Tuesday at 2pm with Dr. Chen" should produce `{date: Tuesday, time: 14:00, provider: "Dr. Chen"}`. Common dates, edge dates ("next Tuesday week"), incomplete extractions, ambiguous extractions — all part of the test set.
Response generation nodes produce natural-language output from structured state. Node-level tests for response generation use LLM-as-judge scoring against a tone and brevity rubric. The judge checks that the response addresses the right field, sounds professional, and stays under a token budget.
What node-level tests cannot catch: state transitions that work in isolation but fail in combination. Tool call sequences that depend on prior conversation state. Latency cliffs across multiple node executions. Behaviour under acoustic conditions. Node-level testing is necessary. It is not sufficient. Teams that ship node-level coverage and call it done are shipping untested voice agents.
Tier 2: Subgraph testing
Subgraph testing is the middle tier most teams skip. It verifies that a complete flow — typically a coherent task like "schedule an appointment" or "reset password" — completes correctly given a synthetic caller. This tier catches a specific category of failures the other tiers miss: state-machine failures that emerge only when nodes interact.
What subgraph tests verify:
- Tool calls happen in the right order with the right arguments — this is tool call verification at the flow level
- State transitions follow conditional edges correctly across the full flow
- Fallback handling triggers when the conversation deviates
- The end state of the conversation matches the expected outcome
- Tool failure modes (timeouts, error codes, rate limits) are handled gracefully without breaking the conversation
Subgraph testing is where ai agent testing meets graph based agent design. Many ai testing tools cover only the node level or only the conversation level. Subgraph testing sits between them and catches a category of failure neither extreme detects. It is where ai agent evaluation gets its highest signal-per-cost ratio.
What subgraph tests use:
- A scenario library: defined goals, expected outcomes, allowed conversational paths
- Synthetic callers with controlled behaviour driven by another LLM
- Deterministic mocks for external systems where appropriate
What subgraph tests cannot catch: real acoustic degradation (because audio is not yet part of the test). Real-time latency under production load. Behavioural failures under unexpected user input. Voice-specific failure modes including interruption handling and accent sensitivity. The subgraph layer verifies the graph's logic. It does not verify the agent's voice behaviour.
This tier is harder to set up than node-level. Synthetic-caller infrastructure has to exist. The scenario library has to be designed. Mocks have to be maintained. The investment pays back in the failure mode it catches: state-machine regressions that would otherwise reach production. Teams running CI with subgraph tests catch the "we added a new fallback condition and broke the booking flow" class of regression at PR time, not at customer-complaint time.
Tier 3: End-to-end voice testing
End-to-end voice testing is the highest-cost, highest-confidence tier and the only tier that determines production readiness. The full agent runs under real voice conditions: real ASR processing real audio, real LLM calls, real TTS, real telephony or WebRTC, real latency. Synthetic callers drive the conversation with realistic acoustic and behavioural characteristics. This is where the failures customers actually experience get caught.
What end-to-end voice tests verify:
- Real ASR behaviour against accent variation, background noise, and varied speech pace
- Interruption handling with realistic barge-in timing
- Total latency across the STT → LLM → TTS pipeline under production-like load, against an explicit latency budget that defines the engagement cliff
- Tool calls executing against real or staged systems with real failure modes
- Outcome verification beyond transcript: did the agent actually create the booking in the system, not just say it did?
- Behaviour under unexpected caller input: clarifications, corrections, off-script questions, mid-call topic shifts
- Scenario success rate measured statistically across many runs per scenario × profile cell
What this tier uses:
- A scenario × profile × runs matrix providing real behavioural coverage
- Synthetic callers configurable across multiple behavioural dimensions
- Real telephony or WebRTC infrastructure with controllable acoustic conditions
- Telemetry metrics scored automatically and LLM-as-judge metrics scored against scenario-specific rubrics
- Downstream state verification beyond what the transcript shows
- Statistical aggregation to a scenario success rate that gates release decisions
- Continuous evaluation against production traffic patterns post-deploy, not just pre-deploy regression testing
This is the tier Evalgent is built for. End-to-end voice evaluation against the full scenario × profile matrix, with the statistical reliability scoring production readiness requires. Tier 3 is where most teams either reach for a platform or skip entirely — and skipping is what produces voice agents that work in demos and fail in production.
How the three tiers compose into a release workflow
The three-tier model is not a checklist. It is a workflow with different cadences for different tiers.
Tier 1 runs on every prompt or node change. Smoke evals complete in minutes and sit in CI. A regression at tier 1 blocks the merge before any other testing happens. Tier 2 runs on every PR merge or release candidate. Subgraph regression tests complete in tens of minutes against the candidate build. A regression here blocks the release before tier 3 starts. Tier 3 runs on every release and on a continuous schedule against production traffic patterns. Full graph based voice agent evaluation completes in hours, with statistical aggregation producing the scenario success rate that gates the production deploy. Post-deploy, the same matrix continues running against sampled production traffic to catch production drift before users notice.
Each tier gates the next. Tiered gating is what makes the workflow tractable. Without it, every change runs the most expensive tests — slow and wasteful. With it, cheap tests catch cheap failures fast, and expensive tests catch the failures only they can catch. This is the pattern test-driven development converged on for traditional software: unit tests in CI, integration tests on commit, end-to-end tests on release. Applied to voice agents, with the additional dimension that the highest tier requires production-grade voice infrastructure most teams do not have in-house. Testing graph based voice agent releases under this tiered workflow is the operational embodiment of the architectural choice itself. The connection to broader eval-driven development is direct: tiered evaluation is what EDD looks like applied to graph-based voice systems specifically.
What goes into the scenario library
The scenario library is the central artefact of tier 3 testing. Without one, end-to-end voice testing has nothing meaningful to measure. With one, every test run produces a comparable scenario success rate that gates the deploy decision honestly. The discipline of scenario design matters more than the count.
A good scenario has five elements:
A defined goal. What does success look like? "Book an appointment with the right provider on the requested date." Not "the conversation completed." Goal definition has to be specific enough that an LLM-as-judge or automated outcome check can verify it.
A success criterion. The downstream state check that proves the goal was met. "Appointment record created with the correct date, time, provider, and confirmation reference." This goes beyond what the transcript shows. The agent claiming it booked the appointment is not evidence the appointment got booked.
Allowed paths. Multiple conversational routes that achieve the goal. Real users do not follow the happy path. A good scenario accepts variations — the user changes their mind, asks a clarifying question, requests escalation. The scenario succeeds if any allowed path reaches the goal state.
Required failure modes. Explicit modes the scenario must handle gracefully: user changes their mind, asks an off-topic question, booking system returns an error, requests escalation, provides incomplete information. Each failure mode is part of the scenario's pass criteria.
Caller profile dimensions. The matrix of acoustic and behavioural conditions the scenario runs against. The scenario is not complete until paired with the profiles it gets run against.
How many scenarios is enough? Thirty to fifty well-designed scenarios usually cover the production failure surface for a transactional voice agent. Going from five to thirty catches roughly an order of magnitude more failures. Going from thirty to a hundred catches diminishing returns and inflates regression runtime. The investment is in scenario design quality, not count.
Why caller profiles matter as much as scenarios
A scenario × 1 caller profile × 1 run is not a test. It is an anecdote. Real testing requires the matrix: each scenario run against multiple caller profiles, multiple times per cell. The profiles encode the conditions production callers actually exhibit. Eight behavioural dimensions are worth varying in any serious voice agent evaluation framework.
Accent. Regional variants affect ASR confidence dramatically. An agent that works on US English may fail on UK English, fail harder on Indian English, fail completely on accented English.
Speech pace. Fast callers stress turn detection and interruption handling. Slow callers stress endpointing and silence tolerance.
Background noise. Clean, mild, heavy. WER under background noise determines whether the agent works in real call centres, real homes, real cars.
Interruption level. Patient, neutral, frequent interruptions. The interruption-handling logic — VAD timing, barge-in behaviour, recovery from cut-off responses — needs varied input to test honestly.
Latency tolerance. Callers hang up at different latency thresholds. A profile that hangs up at 2.5s total response time tests something different from a profile that tolerates 5s.
Language. For multilingual agents, language varies as a profile dimension and as a primary axis of evaluation.
Emotional register. Calm, frustrated, confused. The agent's tone matching and de-escalation logic gets tested only when profiles include emotional variation.
Voice gender and pitch. TTS quality and ASR accuracy vary across input voice characteristics. Profile coverage using only one voice gender misses real production variance.
The scenario × profile × runs matrix produces statistically meaningful scenario success rate. One run is anecdote. Three runs reduce variance enough for soft conclusions. Five-to-ten runs per cell produce the statistical reliability production readiness decisions actually require. This is where the Evalgent product surface lives — Profiles as a first-class abstraction with these eight dimensions, configured per evaluation, paired with Scenarios to produce the matrix.
What scoring looks like at each tier
Different tiers need different scoring approaches. Mixing them — using transcript-only scoring at tier 3, or LLM-as-judge at tier 1 — produces noisy signal that erodes confidence in the entire testing process.
Tier 1 scoring is binary pass/fail on structured output. The intent classifier either produced the right enum or it did not. The extraction node either returned the right JSON or it did not. Direct comparison against expected output. No LLM-as-judge needed.
Tier 2 scoring is outcome-based. Did the flow reach the right end state? Did the tool get called with the right arguments? Did the conversation handle the required failure modes? Mostly deterministic with some LLM-as-judge where conversational paths vary. The score per scenario is binary; the aggregate is a pass rate across the scenario library.
Tier 3 scoring is multi-dimensional. Telemetry metrics measured automatically (latency P50/P95/P99, call duration, silence ratio, interruption count). LLM-as-judge metrics scored against scenario-specific rubrics (tone consistency on a 1–5 scale, instruction adherence binary, knowledge accuracy binary). Outcome verification through downstream state checks. Each scenario × profile × run produces a score; aggregation across runs per cell produces scenario success rate; aggregation across cells produces overall agent quality.
The three scoring approaches map to the three tiers and produce qualitatively different signals. Engineers comparing pre-deploy and post-deploy quality need all three.
Where Evalgent fits in the methodology
The three-tier model is platform-agnostic. The methodology for testing graph based voice agent systems applies whether they are built on LangGraph, Pipecat Flows, Vapi Workflows, Retell Conversation Flows, or custom state machines. Tier 1 and tier 2 can be home-built with reasonable engineering investment — synthetic-caller infrastructure, scenario design, mocks, scoring rubrics. Tier 3 is the layer most teams either reach for a platform or skip entirely.
Evalgent is built specifically for tier 3. The product primitives map directly to the methodology:
- Scenarios — the curated library that defines what the agent must handle, with goals, success criteria, allowed paths, and required failure modes
- Profiles — the 8-dimension behavioural matrix that varies caller conditions, configurable per scenario or per evaluation
- Metrics — telemetry metrics and LLM-as-judge metrics, scored per scenario per profile per run
- Evaluations — the matrix run end-to-end with statistical aggregation to scenario success rate, gating release decisions
- Reviews — surfaced failures with full call recordings, transcripts, downstream state checks, and structured tagging for triage
Teams can build this tier themselves. The investment is non-trivial: scenario library tooling, synthetic caller infrastructure, audio pipeline, telephony integration, scoring rubric design, regression dashboards, statistical aggregation. Estimated three-to-six months of engineering for a team that has not done it before. Or they can use a platform built for exactly this layer. The trade-off is the same as any infrastructure question — own it for control, or use a platform for speed. The methodology is the same either way.
Common testing mistakes for graph-based voice agents
Five testing mistakes recur in graph-based voice agent deployments. Each is preventable with the three-tier methodology.
Stopping at node-level tests. The most common failure mode. Thorough unit tests for each LLM node, green CI, ship. Tier 1 catches the obvious bugs. Production failures live above it.
Subgraph tests against transcript only. Teams building tier 2 testing but checking only the transcript miss failures that depend on downstream state. The agent says "booked." The booking system has no record. Transcript-only scoring misses the most expensive class of failure.
One scenario × one profile × one run. Anecdote, not evidence. A single run tells you nothing about reliability. The agent works once. That is not the same as ninety percent reliable across realistic conditions.
Ignoring caller profile variation. Tests run only against the test team's accents and speech patterns. Production callers do not all sound like the test team. Coverage that does not match the target user population produces false confidence.
No outcome verification. The agent claims success in the transcript. Nobody checks the downstream system. Most production "successes" are unverified — and the consequential failures (appointments at wrong times, payments to wrong accounts) cluster here.
Each of these is fixable with the three-tier methodology. The framework is platform-agnostic. The discipline is what determines whether production ai voice systems reach production readiness.
Summary
Testing graph based voice agent systems requires three tiers. Most teams ship having tested only the first one.
Frequently asked questions
How do you test a graph based voice agent?
How to evaluate a graph based voice agent properly requires three tiers. Node-level tests verify each LLM call against representative inputs. Subgraph tests verify full flows reach the right end state with synthetic callers. End-to-end voice tests verify the agent works under real acoustic conditions with the full scenario × profile matrix. Graph based agents fail in production when teams skip any tier.
What is node-level voice agent testing?
Node level voice agent testing verifies each LLM-driven node in isolation. Intent classification nodes get tested against representative user messages with binary pass/fail on the enum output. Extraction nodes get tested against structured JSON expectations. Response generation nodes get tested with LLM-as-judge scoring against a tone rubric. Node-level testing is necessary but not sufficient.
What is subgraph testing for voice agents?
Subgraph testing voice agent flows verifies that complete tasks — booking, cancellation, account update — execute correctly under synthetic callers. It catches state-machine failures where individual nodes work but their interaction breaks. Tools get called in the right order with the right arguments. Fallbacks trigger when expected. Outcome state matches expectation. Most teams skip this tier.
What is end to end voice agent testing?
End to end voice agent testing puts the full agent through real voice conditions. Real ASR on real audio, real LLM calls, real TTS, real telephony, real latency. Synthetic callers vary across the scenario × profile matrix. Scoring includes telemetry metrics, LLM-as-judge metrics, and downstream state verification. This tier determines production readiness.
How many scenarios should a voice agent test suite have?
Thirty to fifty well-designed scenarios usually cover the production failure surface for a transactional voice agent. Going from five to thirty catches roughly an order of magnitude more failures. Going from thirty to one hundred catches diminishing returns. Investment goes into scenario design quality, not count. Each scenario needs goal, success criterion, allowed paths, and failure modes.
What are caller profiles in voice agent testing?
Caller profiles encode the acoustic and behavioural conditions production callers exhibit. Eight dimensions matter: accent, speech pace, background noise, interruption level, latency tolerance, language, emotional register, voice gender. Each scenario gets run against multiple profiles, multiple times per cell. The matrix produces statistically meaningful scenario success rate rather than anecdotal pass/fail.
What is scenario success rate?
Scenario success rate is the percentage of runs per scenario × profile cell that meet the scenario's success criterion. Aggregated across cells, it produces the overall agent quality metric that gates release decisions. One run produces anecdote. Five-to-ten runs per cell produce the statistical reliability that production readiness decisions require honestly.
Can you test a graph based voice agent with the same tools as a prompt based one?
Partially. Both architectures need end-to-end voice testing under real acoustic and behavioural conditions — that tier is identical. Graph based voice agent testing adds node-level and subgraph tiers that prompt-based architectures cannot support, because prompt-based agents lack the discrete testable surfaces. The third tier is shared. The first two are unique to graph-based.
Related Articles
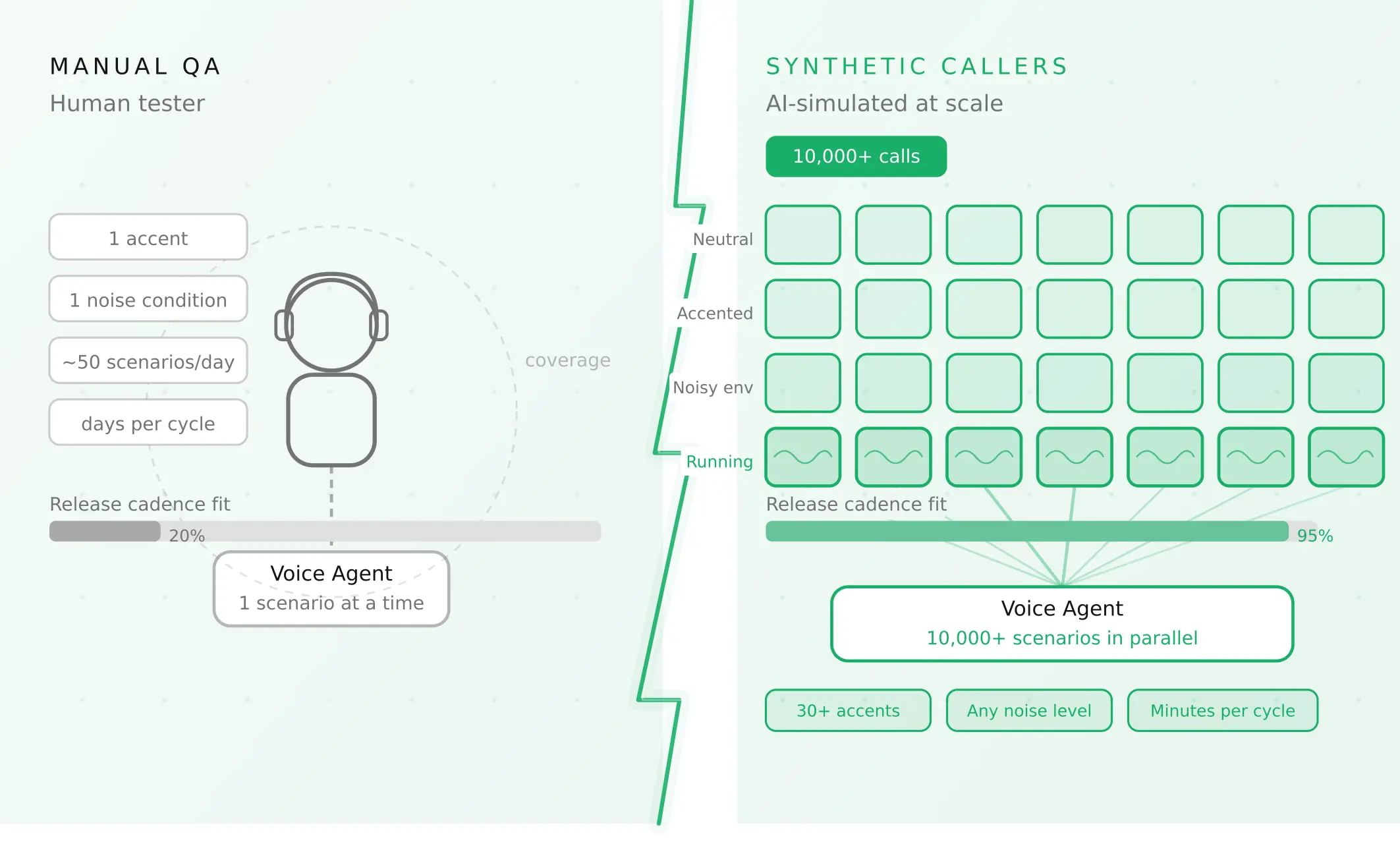
How to automate voice agent testing: synthetic callers vs manual QA
Learn how ai test automation replaces manual QA for voice agents. Compare synthetic callers vs human testers, with a 5-step framework to scale without hiring.
Read more
AI Agent Testing vs Voice Agent Testing: What General Tools Miss for Voice
AI agent testing measures text outputs. Voice agent testing measures behaviour through an acoustic pipeline. Five failure categories general tools miss.
Read more