Test your voice agent
Cascading vs speech-to-speech voice agents: which architecture should you choose?
Every voice agent runs on one of two architectures, and the choice shapes everything after it: latency, cost, voice quality, and how you debug. Cascading vs speech-to-speech is not a vendor question; it is an engineering one that outlasts any single platform. This guide compares the two designs across each axis and gives a clear way to decide, whichever platform you end up on.
Evalgent is architecture-agnostic, so we call the trade-offs straight, without favouring either camp. First, what each one is.
What is a cascading voice agent?
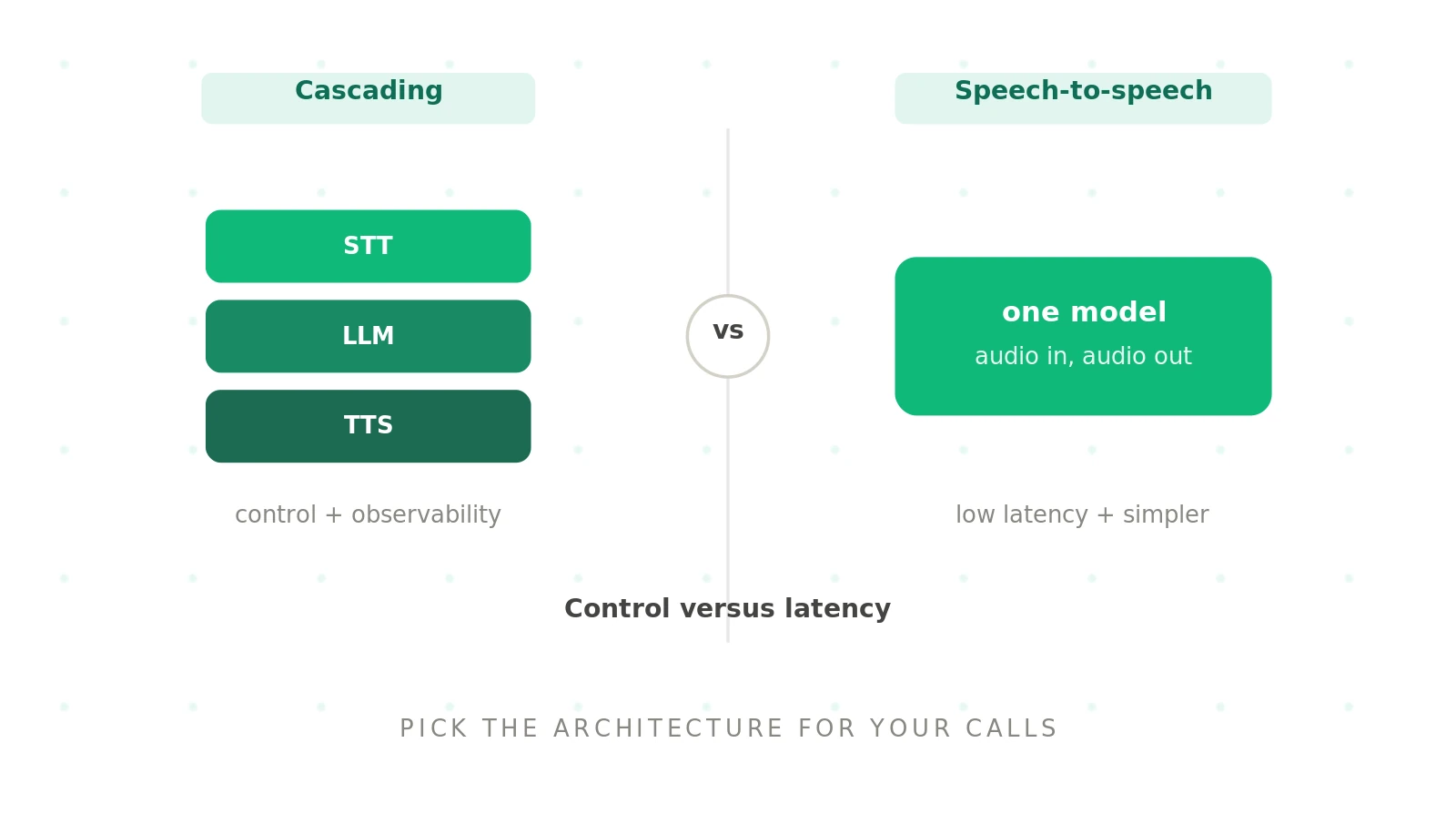
Cascading voice agent: a voice agent that chains three separate models, speech-to-text, an LLM, and text-to-speech, so each stage is a distinct, swappable component.
The cascading design is the classic pipeline. Audio hits a speech recognition model, the text goes to an LLM, and the response passes through a speech synthesis model. A separate turn-taking layer decides when to speak. Our voice agent stack guide breaks down each layer.
The appeal is control. You pick each component, swap any of them, and inspect what happens between them. The cost is complexity: three models, three sets of latency, and hand-offs on every turn.
What is a speech-to-speech voice agent?
Speech-to-speech voice agent: a voice agent built on a single model that takes audio in and emits audio out directly, without separate transcription and synthesis stages.
Speech-to-speech, sometimes called realtime, collapses the pipeline into one model. There is no explicit transcript in the middle. Audio goes in, audio comes out. This is the architecture behind newer offerings like xAI's Grok Voice, covered in our xAI Voice Agent guide, and the xAI Voice page describes the single-model approach.
The appeal is speed and simplicity. One model means no hand-offs, so latency drops and the conversation can feel more natural. It also keeps the vocal nuance and emotion that a transcript flattens away.
Cascading vs speech-to-speech at a glance
The two designs trade the same things in opposite directions. Control against simplicity. Flexibility against latency.
| Factor | Cascading | Speech-to-speech |
|---|---|---|
| Models | STT + LLM + TTS | One model |
| Latency | Higher, multiple hand-offs | Lower, single pass |
| Control | Swap any component | Fixed, unified |
| LLM choice | Pick your own | Built in |
| Observability | Per-stage transcripts | Black box, no mid-transcript |
| Voice nuance | Flattened through text | Preserved |
| Maturity | Battle-tested | Newer |
Neither wins outright. The right pick depends on what you value most.
Latency: where speech-to-speech leads
Latency is the clearest win for speech-to-speech. A cascading agent pays a latency cost at every hand-off: audio to text, text to reasoning, reasoning to audio. Those add up, and the caller feels the pause.
A speech-to-speech model does it in one pass, so sub-second responses are the norm. For latency-critical use cases, interruptions, fast back-and-forth, emotional calls, that matters. This is closely tied to natural turn-taking, which we cover in the full-duplex voice agents guide.
Control and observability: where cascading leads
Cascading wins on control and on seeing inside the system. Because each stage is separate, you can swap the LLM for a cheaper or specialised one, tune the STT for your accents, or change the voice, independently. Our best LLM for voice agents guide covers why model choice often matters.
The bigger advantage is observability. A cascading agent produces a transcript at each stage, so when a call fails you can see whether the error was in transcription, reasoning, or speech. A speech-to-speech agent has no intermediate transcript. It is a black box: you know the call went wrong, but not which internal step caused it. That makes debugging harder.
Cost and voice quality
On cost, the two are converging, but they price differently. Cascading costs are the sum of three providers plus a platform fee. Speech-to-speech is often bundled into one lower rate. Neither is universally cheaper; it depends on your models and volume. A cheap bundled speech-to-speech rate can beat a cascading stack that uses premium components. A tuned cascading stack on budget models can beat a premium speech-to-speech configuration. Run the numbers on your own call mix before assuming one is cheaper.
On voice, there is a subtle trade. Cascading lets you use a best-in-class text-to-speech model, so raw voice quality can be very high. Speech-to-speech preserves tone and emotion that a transcript loses, which can feel more natural even if the voice library is smaller. Which matters more depends on whether your priority is studio polish or human naturalness. Both are valid goals. They just point at different architectures.
When to choose which
Match the architecture to your constraint, not to the newest trend.
- Choose cascading if you need control over each component, want to pick your own LLM, or require per-stage observability for debugging and compliance. It suits complex, regulated, or heavily tuned agents.
- Choose speech-to-speech if you need the lowest latency, a simpler stack, and natural turn-taking, and you do not need to swap the LLM. It suits fast, high-volume conversational calls.
Many production systems are in fact hybrids, using a mostly cascading pipeline with a fast interruption path. The honest answer is a spectrum, and the right point on it is set by your calls. You do not have to be purely one or the other. Many teams keep a cascading core for control and add a realtime path where latency is critical. Design for your hardest calls, then simplify where you can.
The two camps, in plain terms
The debate goes by many names. Pipeline vs speech-to-speech. Sts vs cascading. Realtime vs staged. They all point at the same fork.
Cascading voice agents are the established camp. They stitch three models and give you knobs for each. Most production systems today are cascading. The tooling is mature and well understood.
Realtime voice agents, the speech-to-speech camp, are newer. One model, fewer knobs, lower latency. Grok Voice and similar realtime APIs sit here. They are improving fast.
Your voice agent architecture decision is really about which camp fits your calls. Do you need to tune each stage? Cascading. Do you need the fastest, simplest path? Speech-to-speech. Streaming matters in both: partial transcripts and streamed audio keep either architecture responsive, though a single model has less to stream between stages.
Where this is heading
The gap is closing from both sides. Speech-to-speech models keep gaining control features that cascading offered. Cascading pipelines keep cutting latency toward realtime. The clean divide of a year ago is blurring.
That has a practical consequence. Do not marry an architecture. Pick the one that fits your calls today, and re-check as the models change. A choice that is right this quarter may not be right next year.
It also raises the stakes on evaluation. As both camps get easier to ship, the differentiator is no longer the architecture. It is whether your agent actually handles real calls. Two teams can pick opposite architectures and both ship a good agent, or both ship a bad one. The architecture sets the constraints. Testing decides the outcome.
So treat this decision as important but not final. Build on the architecture that suits your latency, control, and cost needs. Then prove the agent works, because callers do not care which camp you chose. They care whether the call went well.
The step both architectures share: testing
Both designs get an agent built. Neither proves it works with real callers. Accents, interruptions, noise, and edge cases break agents on both architectures, and the testing challenge actually differs between them. A cascading agent can be tested per stage; a speech-to-speech agent, with no intermediate transcript, can only be judged on outcomes.
This is where Evalgent fits. Evalgent runs realistic calls against your agent whatever its architecture, and measures what the caller experiences. Scenarios reproduce noisy, accented, and off-script calls. Profiles vary caller behaviour so results split per cohort. Metrics score task completion, latency, and adherence with thresholds. Because it evaluates the whole call, it works even for a black-box speech-to-speech model. For the full method, see the ai voice agent testing pillar.
Frequently asked questions
What is a speech-to-speech voice agent?
A speech-to-speech voice agent runs on a single model that takes audio in and emits audio out directly, without separate speech-to-text and text-to-speech stages. Sometimes called realtime, it collapses the usual pipeline into one model, which lowers latency and preserves vocal nuance. The trade-off is less control over each stage and no intermediate transcript to inspect when a call fails.
What is a cascading voice agent?
A cascading voice agent chains three separate models: speech-to-text to transcribe the caller, an LLM to reason and respond, and text-to-speech to speak the reply, with a turn-taking layer deciding when to talk. Each stage is a distinct, swappable component, which gives control and per-stage observability, at the cost of higher latency from the hand-offs between models.
Cascading vs speech-to-speech which is better?
Neither is universally better. Cascading chains STT, an LLM, and TTS, giving control, LLM choice, and per-stage observability, at higher latency. Speech-to-speech uses one model for lower latency, a simpler stack, and preserved vocal nuance, but with less control and no intermediate transcript. Choose cascading for control and debugging, speech-to-speech for latency and simplicity.
Is speech-to-speech lower latency than cascading?
Yes, speech-to-speech is generally lower latency than cascading. A cascading agent pays a latency cost at every hand-off between the speech-to-text, LLM, and text-to-speech stages, and those add up. A speech-to-speech model responds in a single pass, so sub-second responses are typical. For interruption-heavy or fast back-and-forth calls, that latency advantage is meaningful.
Does cascading give more control than speech-to-speech?
Yes. A cascading architecture lets you swap each component independently, so you can choose your own LLM, tune the speech-to-text for your accents, or change the voice model. A speech-to-speech agent is a single unified model, so you cannot substitute its parts. Cascading also gives per-stage transcripts for debugging, while speech-to-speech offers no intermediate visibility.
When should you use a speech-to-speech voice agent?
Use a speech-to-speech voice agent when you need the lowest latency, a simpler stack, and natural turn-taking, and you do not need to pick your own LLM or inspect each stage. It suits fast, high-volume conversational calls where responsiveness matters most. For agents that need component control, a specific LLM, or per-stage observability, a cascading architecture is usually the better fit.
What are the downsides of speech-to-speech voice agents?
The main downsides of speech-to-speech voice agents are reduced control and observability. You cannot swap the LLM or tune a single stage, because the model is unified. There is no intermediate transcript, so when a call fails you cannot see which internal step caused it, which makes debugging harder. The architecture is also newer, with a shorter production track record.
How do you test a cascading vs speech-to-speech agent?
Test a cascading agent both per stage and end to end, since you have transcripts at each step. Test a speech-to-speech agent on outcomes only, because it has no intermediate transcript to inspect. In both cases, run realistic calls with accents, noise, and interruptions and measure task completion and latency per cohort. Full-call, outcome-based testing works for either architecture.
Conclusion
Cascading vs speech-to-speech is a trade between control and simplicity. Cascading chains three models for flexibility and per-stage observability; speech-to-speech uses one model for lower latency and a simpler, more natural conversation. There is no universal winner here, only the architecture that best fits your calls.
Whichever you choose, the agent still has to survive real callers. Test it end to end under real conditions, because a black-box speech-to-speech model and a tunable pipeline both fail in production without it.
Related Articles

Why AI voice agents fail in production (and how to prevent it)
AI voice agents that ace demos still break in production. Learn the 5 root causes, how to test for each, and what production readiness actually means.
Read more
Voice agent regression testing: why LLM updates break production
LLM updates improve benchmarks but break voice agents in 5 predictable ways. How to detect and prevent regressions after every model or prompt change.
Read more