Test your voice agent
AI voice agent testing: the complete guide
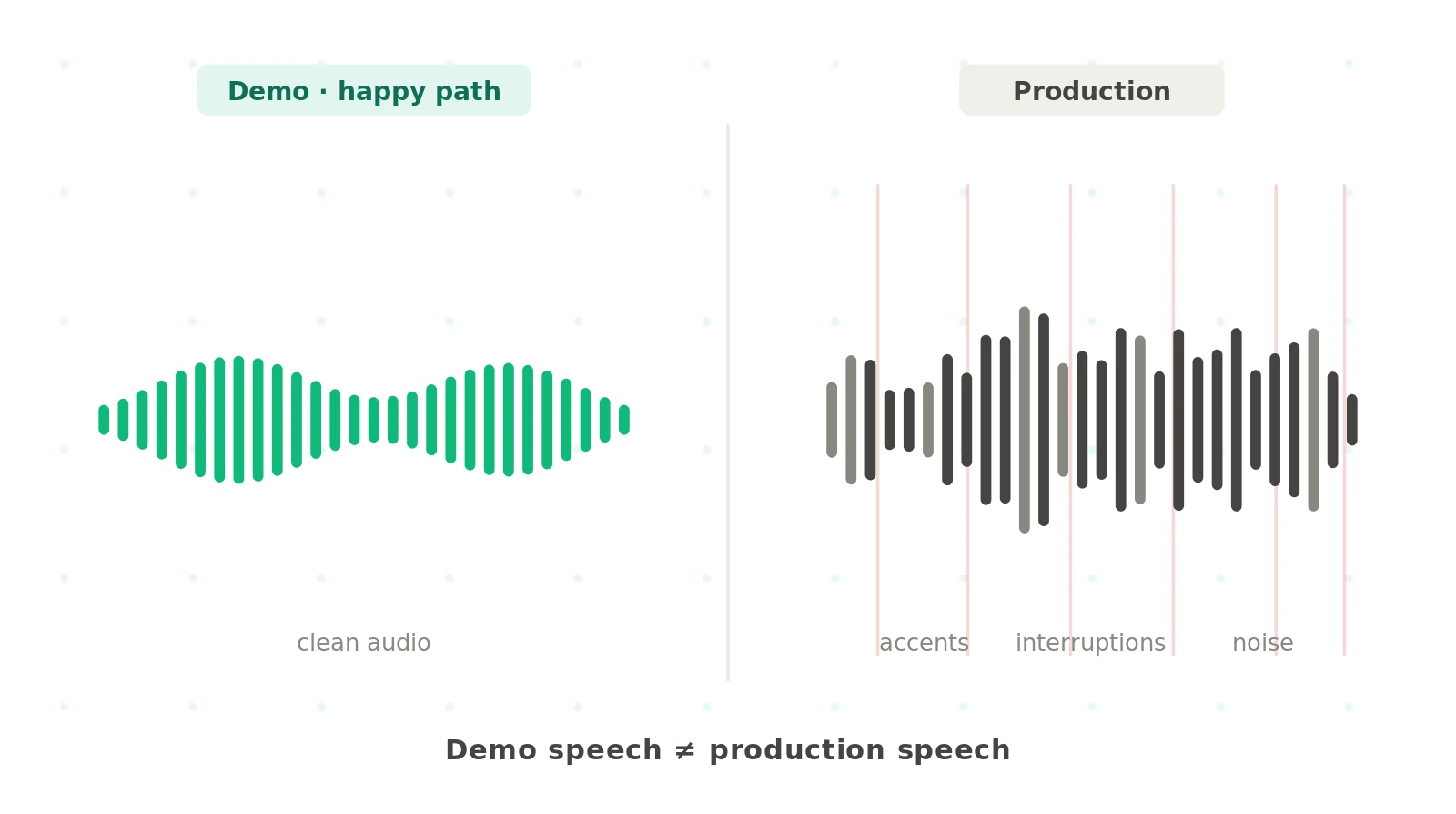
Most teams test the wrong layer of their voice agent. They check the prompt and the happy path. Then real callers talk over the agent, speak with an accent, or pause mid-sentence, and the agent breaks. AI voice agent testing exists to catch those failures first.
This guide covers what to test, which metrics matter, and how to choose a platform. Evalgent built its product around this exact problem, so we will be specific about the behavioural failures that slip past traditional checks. If you are new to the category, start with our explainer on what a voice agent is, then come back here.
What is AI voice agent testing?
AI voice agent testing: the process of evaluating a voice agent across the full speech pipeline, from audio in to audio out, under realistic caller conditions. It measures whether the agent hears correctly, responds sensibly, and recovers gracefully.
Text agent testing reads inputs and outputs. Voice agent testing has to account for sound. Audio enters through speech-to-text, passes through a language model, and exits through text-to-speech. Each stage can fail on its own. Worse, errors compound down the chain.
A small transcription error becomes a wrong intent. A wrong intent becomes a wrong answer. The caller hears a confident, fluent, completely incorrect response. This is why voice ai testing is harder than it looks. The agent can sound perfect and still be wrong.
Evalgent approaches this with synthetic callers that speak to your agent over real audio. The point is to test the behaviour a live caller would trigger, not the transcript you hoped for.
Why voice agents are harder to test than text agents
Voice adds variables that text never has. The same sentence arrives a hundred different ways. People mumble, rush, repeat themselves, and interrupt. Background noise rides along with the words.
Three properties make voice agent testing distinct:
- Acoustic variance. Accents, pace, pitch, and noise all change the input audio. Your test set has to reflect that range.
- Timing. Voice is real-time. A two-second pause feels broken. Latency is a correctness issue, not just a comfort one.
- Turn-taking. Callers interrupt. The agent must detect the interruption, stop talking, and listen. This is barge-in, and it fails constantly in production.
Text harnesses ignore all three. That gap is the reason a voice agent can pass every text check and still fail a real call. For a deeper split of the two disciplines, see AI agent testing vs voice agent testing.
What to test: the layers of a voice agent
A voice agent is a pipeline, and each layer needs its own checks. Understanding the stack tells you where to point your test scenarios. Our voice agent stack guide breaks down each component in detail.
- Speech-to-text (STT). Measure STT accuracy against real audio, not clean studio clips. Word error rate climbs fast with noise and accents.
- Language model. Check intent, reasoning, tool calls, and grounding. This is where hallucinations enter.
- Text-to-speech (TTS). Verify clarity, pacing, and pronunciation of names and numbers.
- Turn-taking and VAD. Test voice activity detection, turn detection, and interruption handling under overlap.
- Telephony. Confirm the agent survives jitter, dropped packets, and codec changes on the carrier.
Test each layer in isolation, then test them together. Component checks find the root cause. End-to-end checks prove the caller experience.
The five dimensions of voice agent testing
Comprehensive voice agent evaluation covers five dimensions. Skip one and you ship a blind spot.
1. Accuracy. Does the agent hear and understand correctly across voices and noise?
2. Latency. Does it respond fast enough to feel natural? Measure latency at the median and the tail.
3. Interruption handling. Does barge-in work when the caller cuts in mid-response?
4. Edge cases. Does the agent handle silence, gibberish, hostile callers, and off-script requests?
5. Behaviour. Does it follow policy, escalate correctly, and stay on task across a long call?
The first four are common in any voice agent testing tools discussion. The fifth is where most products stop and where Evalgent focuses. Behaviour under real caller pressure is the failure mode that demos never show.
Automated voice agent testing vs manual QA
Manual QA means a person calls the agent and listens. It is useful early and impossible to scale. Automated voice agent testing uses synthetic callers to run hundreds of scenarios on every change. Most mature teams use both, but the balance shifts toward automation fast.
| Factor | Manual QA | Automated voice agent testing |
|---|---|---|
| Coverage per run | A handful of calls | Hundreds of scenarios |
| Cost to repeat | High, every time | Near zero after setup |
| Accent and noise range | Limited to staff | Broad, by design |
| Regression safety | Misses silent breaks | Catches them on each run |
| Best for | Exploratory checks | Release gates and scale |
Manual testing is right for early exploration and tricky one-off bugs. Automation is right for release gates, regression safety, and any team shipping weekly. Evalgent runs scenario batches as synthetic callers, so a full suite reruns on every prompt or model change. Our piece on synthetic callers versus manual QA goes deeper on the trade-off.
Metrics and pass/fail thresholds
Good voice agent testing turns vague impressions into numbers with thresholds. You cannot defend "it sounds fine." You can defend a metric that crosses a line. Set thresholds before you test, then gate releases on them.
Track these core metrics:
- Word error rate (WER). The share of words the agent transcribes wrong. WER is the standard accuracy measure for STT.
- Latency. Time to first response, reported at P50, P90, and P99. The tail matters more than the average.
- Task completion. Did the caller achieve their goal without a human?
- Containment rate. The share of calls handled without escalation to a person.
- Interruption recovery. How often barge-in is detected and handled correctly.
Set pass/fail thresholds per metric and per scenario. A banking agent and a pizza line tolerate different error rates. Thresholds encode that judgement. Evalgent lets you define custom metrics and thresholds per scenario, so your release gate reflects your risk, not a generic default.
Be careful with LLM-as-judge scoring of transcripts. It is convenient, but it rates the words, not the call. An agent can earn a high transcript score while the caller hangs up in frustration. Pair model scoring with outcome metrics, never rely on it alone.
How to test voice agents for accents and dialects
Accents are where clean demos meet messy reality. An agent trained and tested on one accent degrades sharply on others. Your test set has to span the voices your callers actually use.
Build accent and dialect coverage deliberately:
- Source synthetic callers across the regions and languages you serve.
- Include code-switching, where a caller mixes two languages in one sentence.
- Stress the agent with regional vocabulary, slang, and name pronunciation.
- Track WER per accent group, not just an overall average.
A single blended score hides the worst group. Report metrics per cohort so a failing accent cannot disappear inside a healthy mean. This is exactly the kind of voice activity detection and transcription stress that separates a real test suite from a checkbox.
What's the difference between voice agent test cases and assertions?
This distinction trips up teams new to voice agent qa. A test case is the scenario. An assertion is the rule that decides if the agent passed.
Test case: a defined caller scenario, such as an angry customer disputing a charge while background noise plays. It sets up the conditions and the caller behaviour.
Assertion: a checkable claim about the agent's behaviour in that scenario, such as "the agent offered to escalate within two turns" or "WER stayed under threshold."
One test case usually carries several assertions. The scenario creates the pressure. The assertions decide the verdict. Good voice agent testing tools let you write assertions about behaviour and outcomes, not only about the transcript text.
Regression testing after model or prompt updates
A model upgrade can improve benchmarks and quietly break your agent. New weights change behaviour you depended on. So does a small prompt edit. Regression testing catches the silent breaks before callers do.
Run your full scenario suite on every change:
- After any LLM version change.
- After prompt edits, even one-line ones.
- After swapping STT, TTS, or telephony providers.
- Before every production release.
Compare results against the last known-good run and flag any metric that slipped. This is how teams keep production readiness from eroding one update at a time. Our deep dive on LLM update regressions shows the five ways model updates break live agents.
How to choose a voice agent testing platform
The market now has many voice agent testing tools, from general agent eval frameworks to voice-specific platforms. The right choice depends on how you ship and how much real-world behaviour you need to cover.
Use this checklist when you compare a voice agent testing platform:
- Real audio, not transcripts. Does it test over speech, with synthetic callers, or just grade text?
- Behavioural coverage. Can it test interruptions, accents, noise, and edge cases, not only intent?
- Custom metrics and thresholds. Can you define pass/fail rules per scenario?
- Regression workflow. Does it rerun suites automatically on every change?
- Review tooling. Can your team inspect failures with audio, transcript, and metrics together?
General agent testing frameworks cover the language model well but miss the acoustic layer. Voice-specific platforms cover the call. For teams whose agents take real phone calls, the acoustic and behavioural coverage is the deciding factor.
Testing voice agents with Evalgent
Evalgent is a voice agent testing platform built for the behavioural layer that other tools skip. It runs realistic conversations against your agent and measures what the caller actually experiences. Five primitives carry the workflow.
- Scenarios define real-world test conversations, from happy paths to hostile callers.
- Profiles configure caller personas, accents, and behaviours.
- Metrics let you measure what matters with custom, per-scenario thresholds.
- Evaluations run automated batches as synthetic callers on every change.
- Reviews let your team inspect and analyse results with audio and transcript side by side.
Together they turn voice agent testing into a repeatable release gate. You define the calls that scare you, run them on every change, and ship only when the agent passes.
Frequently asked questions
What is AI voice agent testing?
AI voice agent testing is the practice of verifying a voice agent through real speech rather than text alone. It evaluates transcription, reasoning, response timing, and recovery across accents, noise, interruptions, and edge cases. The goal is to confirm the agent behaves correctly with real callers before it reaches production.
How do you test an AI voice agent before going live?
Test an AI voice agent before going live by running realistic scenarios over real audio. Cover accents, background noise, interruptions, and off-script requests. Set pass/fail thresholds for metrics like word error rate and latency. Rerun the full suite on every prompt or model change, and gate the release on the results.
Automated voice agent testing vs manual QA: which is better?
Automated voice agent testing scales to hundreds of scenarios on every change, while manual QA covers only a handful of calls per run. Manual testing suits early exploration and tricky one-off bugs. Automation suits release gates, regression safety, and weekly shipping. Most mature teams use both, weighted heavily toward automation.
What metrics matter in voice agent testing?
The metrics that matter most are word error rate for transcription accuracy, latency at P50, P90, and P99, task completion rate, and containment rate. Add interruption recovery for barge-in. Set thresholds per scenario, since a banking agent and a food-ordering line tolerate very different error rates.
How do you test voice agents for accents and dialects?
Test voice agents for accents and dialects by sourcing synthetic callers across the regions and languages you serve. Include code-switching and regional vocabulary. Track word error rate per accent group rather than one blended average. A single overall score hides the worst-performing cohort, so always report metrics per group.
What should you look for in a voice agent testing platform?
Look for a voice agent testing platform that tests over real audio with synthetic callers, not just transcripts. It should cover interruptions, accents, noise, and edge cases. Confirm it supports custom metrics and thresholds, automatic regression runs on every change, and review tooling that shows audio, transcript, and metrics together.
What is the difference between voice agent test cases and assertions?
A voice agent test case is the scenario, such as an angry caller disputing a charge in a noisy room. An assertion is the rule that decides pass or fail, such as the agent escalating within two turns. One test case usually carries several assertions. The scenario sets the pressure; the assertions decide the verdict.
How is voice agent regression testing done after an LLM update?
Voice agent regression testing after an LLM update means rerunning your full scenario suite against the new model. Compare every metric to the last known-good run and flag any that slipped. Do the same after prompt edits and provider swaps. This catches silent behavioural breaks that improved benchmarks can hide.
Conclusion
AI voice agent testing succeeds or fails on one thing: testing real speech under real conditions, not clean text. The agents that survive production are the ones tested against accents, interruptions, noise, and edge cases before launch.
Decide the calls that worry you most, write them as scenarios, and attach metrics with thresholds. Run that suite on every change and gate releases on the result. That discipline, more than any single model, is what keeps a voice agent reliable once real callers start talking.
Related Articles
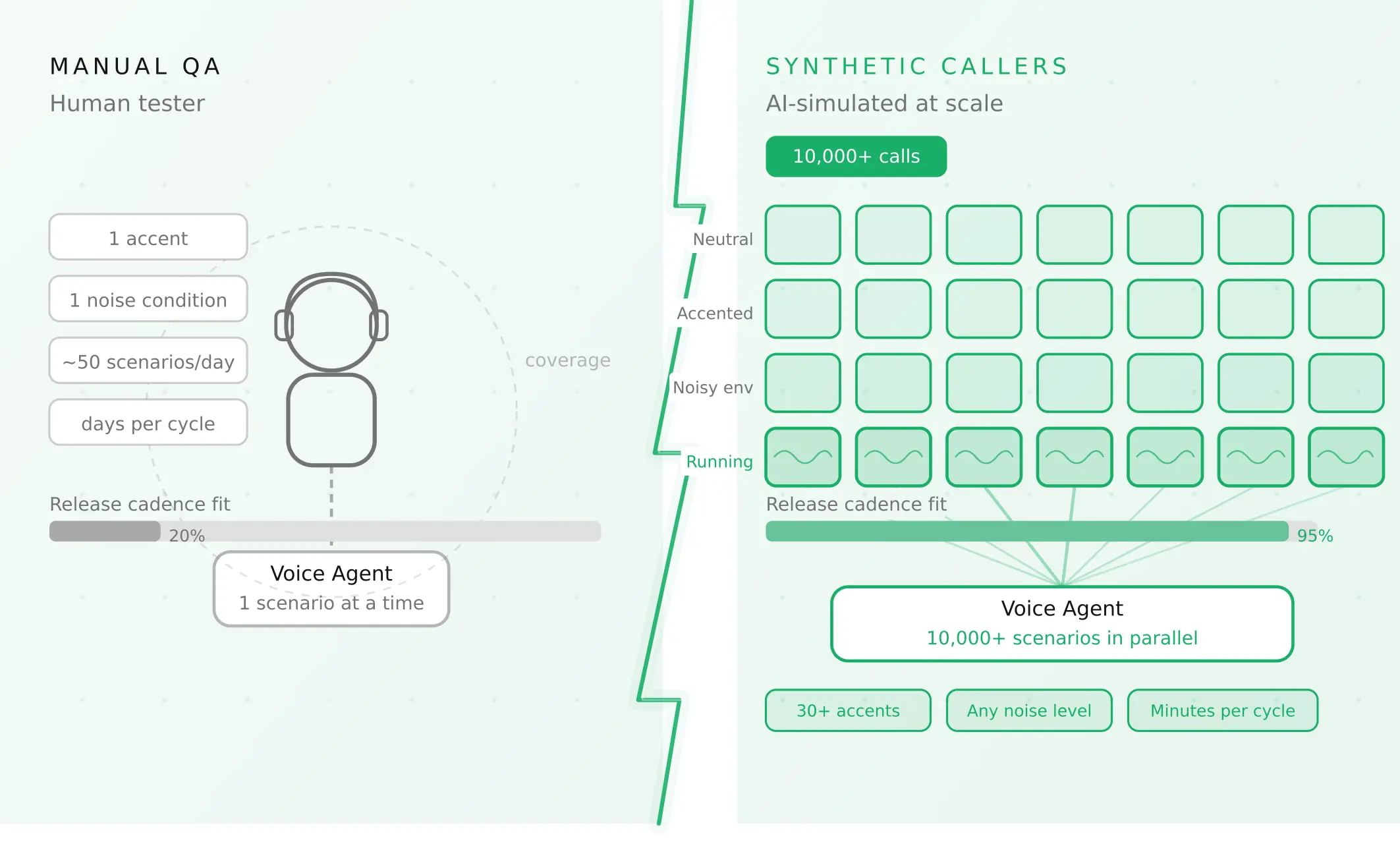
How to automate voice agent testing: synthetic callers vs manual QA
Learn how ai test automation replaces manual QA for voice agents. Compare synthetic callers vs human testers, with a 5-step framework to scale without hiring.
Read more
AI Agent Testing vs Voice Agent Testing: What General Tools Miss for Voice
AI agent testing measures text outputs. Voice agent testing measures behaviour through an acoustic pipeline. Five failure categories general tools miss.
Read more