Test your voice agent
xAI Voice Agent vs ElevenLabs: which voice platform should you choose?
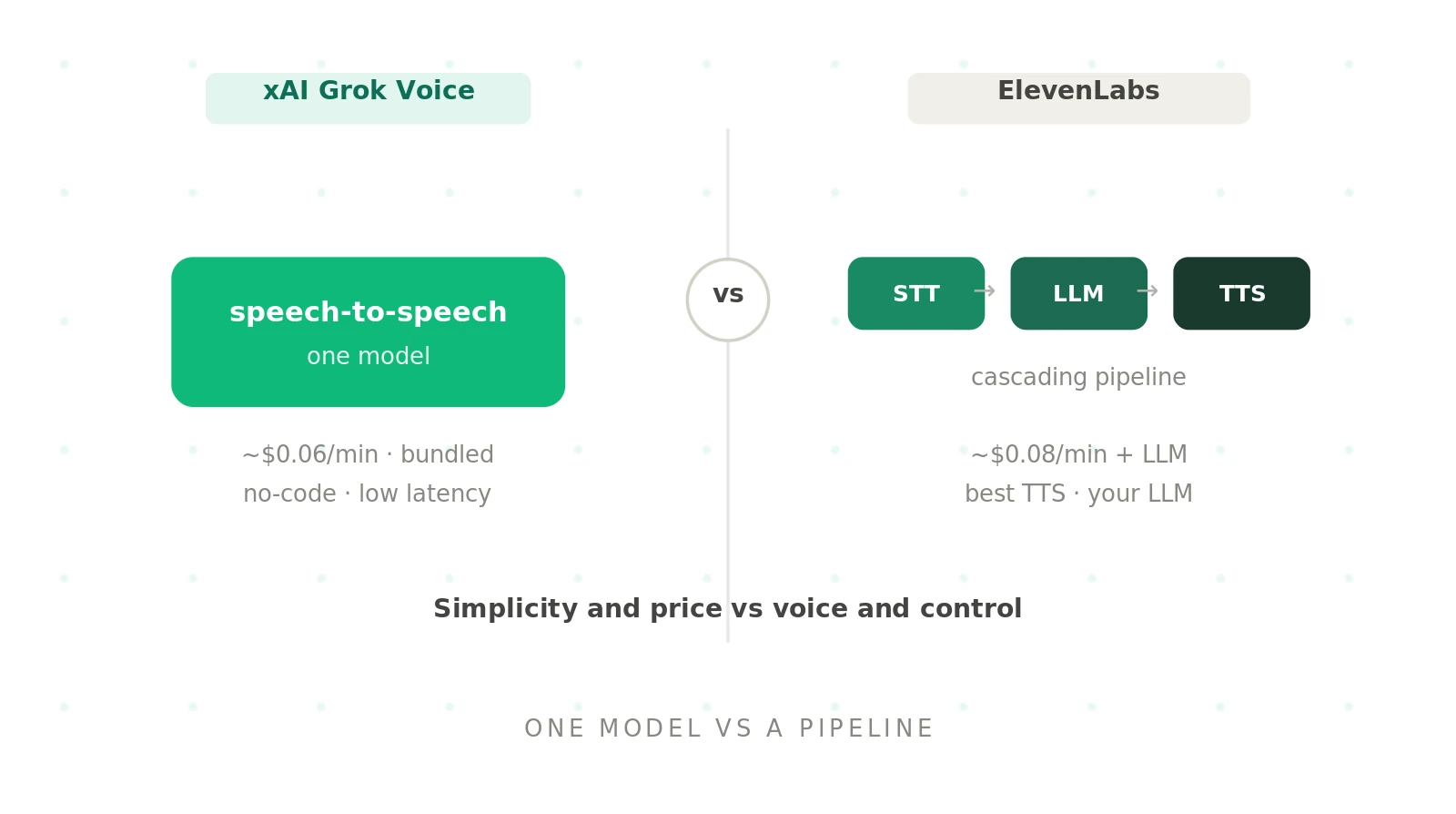
Both platforms let you ship a phone agent, but they are built differently underneath. Grok Voice vs ElevenLabs is really single-model versus pipeline. That choice shapes latency, voice quality, control, and cost. This guide compares them across pricing, voice, architecture, and control, and gives a clear way to decide. Details come from each vendor's own pages, so confirm the current specifics before you commit to either.
Evalgent is platform-agnostic, so we call the trade-offs straight, without favouring either vendor. First, the summary at a glance.
Grok Voice vs ElevenLabs at a glance
The two take opposite approaches. xAI bundles everything into one model. ElevenLabs assembles best-of-breed parts. The table shows where they diverge.
| Factor | xAI Grok Voice | ElevenLabs ElevenAgents |
|---|---|---|
| Architecture | Single speech-to-speech model | Cascading STT + LLM + TTS pipeline |
| Pricing | ~$0.05–$0.06/min all-in | ~$0.08/min + LLM |
| Voice quality | 80+ voices, strong | 5,000+ voices, best-in-class TTS |
| Languages | 25+, mid-call switching | 70+ |
| LLM | Grok Voice, fixed | Your choice of LLM |
| Latency | Sub-second, single model | Sub-second, ~75ms TTS |
| Setup | No-code, ~2 minutes | Fast, pipeline you configure |
For the xAI side in depth, see our xAI Voice Agent guide. The two are close on latency, and both do telephony. So the real differences are architecture, voice, and control. Everything else follows from those three. Keep them in mind as we go layer by layer, because the headline specs matter less than how each one behaves on your calls.
Architecture: single speech-to-speech vs cascading pipeline
This is the core of the comparison. xAI runs one speech-to-speech model: audio goes in, audio comes out, no hand-offs. ElevenLabs runs a cascading pipeline of four parts, a fine-tuned STT model, your chosen LLM, a low-latency TTS model, and a proprietary turn-taking model.
Each design has a logic. Single speech-to-speech is simpler and inherently low-latency, because nothing is stitched together on every turn. A cascading pipeline gives you control over each stage and lets you swap components, at the cost of more moving parts. Single speech-to-speech vs cascading pipeline is the decision underneath the brand names.
Pricing compared
Pricing reflects the architecture. xAI bundles the model and voices into one rate. ElevenLabs charges for agent minutes and passes the LLM through.
Grok Voice is billed around $0.05 per minute with voices included, plus about $0.01 for telephony, so roughly $0.06 all-in. ElevenLabs prices agent minutes near $0.08, per the ElevenLabs agents pricing page. The LLM is billed separately on top. So grok voice vs elevenlabs pricing usually favours xAI on the headline number, though your LLM choice and voice tier move ElevenLabs up or down. Our AI voice agent cost guide puts both in context. Confirm current rates, since both change.
Voice quality and languages
This is ElevenLabs' home turf. It is known for best-in-class text-to-speech. It offers over 5,000 voices and 70-plus languages. Both platforms support voice cloning. If voice realism is your top priority, ElevenLabs is hard to beat.
xAI is strong here too, with 80-plus built-in voices, 25-plus languages, and mid-conversation language switching. For most support and sales calls its voices are more than good enough. But on raw voice library size and language count, ElevenLabs leads. How much that matters depends on whether premium voice quality is central to your brand. Test both on your own scripts, as our TTS evaluation guide describes.
LLM flexibility
Here the pipeline design pays off. ElevenLabs lets you bring your own LLM, so you can pick a cheaper, smarter, or specialised model, and swap it as the landscape changes. That flexibility suits teams with strong model preferences.
xAI's single speech-to-speech model is fixed: you get Grok Voice, which topped the audio benchmarks xAI cites, but you cannot substitute the language model. That is simpler, and the model is strong, but it is a constraint. If model choice matters to you, weigh it, and see our best LLM for voice agents guide for why it often does.
Latency and setup
Both platforms are fast. xAI's single model delivers sub-second responses by design. ElevenLabs reports roughly 75ms TTS latency and sub-second turnaround across its pipeline. In practice, latency is close, and you should measure it on your own calls rather than trust a spec.
Setup differs more. xAI is no-code and goes live in about two minutes from a plain-language brief. ElevenLabs is also quick, but you configure a pipeline and choose components. Both offer SIP telephony, MCP tools, and guardrails, per the xAI Voice and ElevenLabs agents pages. xAI wins on speed to first agent; ElevenLabs wins on configurability.
Which should you choose?
Match the platform to your priority, not to the newer logo.
- Choose xAI Grok Voice if you want the simplest path, the lowest bundled price, low latency, and a fast no-code launch. It suits high-volume support, sales, and scheduling where you do not need to pick the LLM.
- Choose ElevenLabs if voice quality is central, you want to bring your own LLM, or you need the widest voice and language coverage. It suits brands where the voice is the product and teams that want pipeline control.
For many teams either can ship a good agent. The deciding factor is whether you value bundled simplicity or best-of-breed control. Be honest about which you actually need. A team without a strong LLM preference gains little from the pipeline's flexibility. A brand built on a signature voice gains a lot from ElevenLabs' voice library. Note that xAI's platform is newer and in beta, with a shorter production track record than the established ElevenLabs.
How to read this comparison
Searches for elevenlabs vs grok voice and xai vs elevenlabs point at the same decision. It is not really about brand. It is about architecture. One model, or a pipeline.
ElevenLabs conversational AI, branded ElevenAgents, is the pipeline camp. It chains best-of-breed parts. You get control and top voice quality. You also manage more pieces.
Grok Voice is the single-model camp. It is simpler and cheaper to run. You give up component control. So speech-to-speech vs pipeline is really a choice about how much you want to tune.
Frame this voice agent comparison around your constraint. Do you need the best voice? Pick the pipeline. Do you need the fastest, simplest launch? Pick the single model. Do you need a specific LLM? Only the pipeline gives you that. Answer those, and the platform picks itself.
A note on maturity
One more factor sits outside the feature table. ElevenLabs has run conversational agents at scale for a while. Its pipeline is battle-tested. Grok Voice launched in beta in 2026. It is promising and fast, but young.
That gap matters for production. A newer platform can change pricing, features, or limits during beta. It has fewer public deployments to learn from. None of that makes it a bad choice. It just means you carry a little more risk. So test more, not less, before you trust it with real calls.
The step both platforms skip: testing
Both get an agent live. Neither proves it works with real callers. This is the same demo-to-production gap that breaks agents on any platform: accents, interruptions, noise, and edge cases that no builder surfaces for you.
This is where Evalgent fits. Evalgent is platform-agnostic voice agent testing that runs realistic calls against your agent, whether it is built on Grok Voice, ElevenLabs, or anything else. Scenarios reproduce noisy, accented, and off-script calls. Profiles vary caller behaviour so results split per cohort. Metrics score task completion, latency, and adherence. Evaluations run this as automated batches of synthetic callers, and Reviews let your team hear where the agent struggled. Whatever you build on, test before real callers do. See the ai voice agent testing pillar for the method.
Frequently asked questions
xAI Voice Agent vs ElevenLabs which is better?
Neither is universally better. xAI Grok Voice uses a single speech-to-speech model, bundled near $0.05 to $0.06 per minute, favouring low latency and no-code simplicity. ElevenLabs uses a cascading pipeline with best-in-class text-to-speech and your choice of LLM, near $0.08 plus the LLM, favouring voice quality and control. The right pick depends on whether you value simplicity or best-of-breed flexibility.
Grok Voice vs ElevenLabs pricing: which is cheaper?
Grok Voice is usually cheaper on the headline number, at about $0.05 per minute with voices included, plus roughly $0.01 for telephony, so around $0.06 all-in. ElevenLabs prices agent minutes near $0.08 and passes the LLM through separately, so its total depends on the model you pick. For a simple bundled cost, xAI tends to win; confirm both on their pricing pages.
Which has better voice quality grok or ElevenLabs?
ElevenLabs is known for best-in-class text-to-speech, with over 5,000 voices and 70-plus languages, so on raw voice quality and library size it leads. xAI Grok Voice is strong too, with 80-plus voices, 25-plus languages, mid-call switching, and cloning, and is more than good enough for most support and sales calls. If premium voice realism is central to your brand, ElevenLabs is the safer pick.
Single speech-to-speech vs cascading pipeline: what is the difference?
A single speech-to-speech model, like xAI's Grok Voice, takes audio in and emits audio out through one model, which lowers latency and simplifies the stack. A cascading pipeline, like ElevenLabs, chains a speech-to-text model, an LLM, and a text-to-speech model, giving more control over each stage and letting you swap components, at the cost of more moving parts and hand-offs.
Is Grok Voice cheaper than ElevenLabs?
Grok Voice is generally cheaper on the bundled rate, at roughly $0.06 per minute all-in with voices included. ElevenLabs charges around $0.08 per minute for agent minutes plus the LLM separately, so its all-in cost is usually higher, though it varies with your model and voice choices. For predictable, low per-minute cost, xAI has the edge; confirm current rates on each page.
Which supports more languages grok or ElevenLabs?
ElevenLabs supports more languages, with 70-plus, compared with xAI Grok Voice's 25-plus. Both handle multilingual conversations, and Grok Voice can switch language mid-call without manual configuration. If you serve many markets in many languages, ElevenLabs' broader coverage is an advantage. For a smaller set of major languages, either platform is likely sufficient, so test on your actual language mix.
Which is easier to set up grok or ElevenLabs?
xAI Grok Voice is the easier setup for a first agent. It is no-code and compiles a plain-language brief into a live agent in about two minutes. ElevenLabs is also quick but expects you to configure a pipeline and choose components. xAI trades some configurability for speed, so it wins on time to first agent, while ElevenLabs offers more control during setup.
Do you still need to test Grok Voice or ElevenLabs?
Yes. Both platforms get an agent built, but neither proves it works with real callers. Accents, interruptions, noise, and edge cases break agents on every platform, and a newer platform like Grok Voice has a shorter track record. Platform-agnostic testing with synthetic callers, such as Evalgent, verifies the agent under real conditions before launch, whichever you choose.
Conclusion
xAI Voice Agent vs ElevenLabs comes down to single-model simplicity versus best-of-breed control. Choose xAI Grok Voice for bundled low pricing, low latency, and a fast no-code launch. Choose ElevenLabs for top voice quality, your own LLM, and the widest language coverage.
The platform decision matters less than what comes after it. Whichever you pick, the agent still has to survive real callers, and that only gets proven through testing. Pick the platform, then build the test suite that proves it works.
Related Articles

Why AI voice agents fail in production (and how to prevent it)
AI voice agents that ace demos still break in production. Learn the 5 root causes, how to test for each, and what production readiness actually means.
Read more
Voice agent regression testing: why LLM updates break production
LLM updates improve benchmarks but break voice agents in 5 predictable ways. How to detect and prevent regressions after every model or prompt change.
Read more