Test your voice agent
LiveKit voice agent testing guide: what to check before going live
LiveKit is the real-time infrastructure powering voice AI at Meta, OpenAI's ChatGPT Voice, and Character.ai. Its open-source WebRTC stack handles the transport layer. LiveKit Agents — the voice agent framework — went 1.0 in April 2025 and is on v1.5.x as of April 2026, with adaptive interruption handling and native MCP tool support now shipped.
Teams choose it over managed platforms like Vapi or Retell for three reasons: cost at scale (above roughly 10,000 minutes per month, the open source voice agent framework path undercuts managed platforms by 60–80% per call), vendor freedom (bring your own STT, LLM, and TTS — no lock-in), and telephony ownership (native SIP and Phone Numbers shipped in 2025, so inbound and outbound calling no longer requires a Twilio bridge).
The tradeoff: it is infrastructure, not a product. You are building the stack, not configuring one. That flexibility is its strength and its primary source of production failures — there is no managed layer to absorb mistakes, no support contract to escalate to, and no opinionated default to fall back on when something breaks.
This livekit tutorial covers what to test in your voice agent before going live — and the five failure modes specific to how the framework works.
What LiveKit Agents actually is in 2026
This livekit review covers the full picture: two distinct products that are often conflated.
LiveKit is the open-source WebRTC server — a media router (SFU) handling real-time audio and video transport. It runs on LiveKit Cloud or self-hosted on your own infrastructure. The livekit self hosted path eliminates per-minute fees entirely — you pay only your own infrastructure costs. Above roughly 5M minutes per month, self-hosting becomes economically dominant.
LiveKit Agents is the voice agent framework built on top. It lets you add Python or Node.js worker processes to rooms as real-time participants — your agent joins, processes audio through an STT-LLM-TTS pipeline, and publishes responses back. The framework handles turn detection, interruption management, tool calling, and multi-agent handoff. It is fully open source (MIT licensed) and supports 200+ model providers via plugins.
The livekit cloud managed service charges:
| Cost component | Rate |
|---|---|
| Agent session minutes | $0.01/min |
| SIP minutes | $0.003–0.004/min |
| WebRTC minutes | $0.0004–0.0005/min |
| Audio transcode | $0.004–0.005/min |
| Inference (LLM/STT/TTS via LiveKit) | Per model/token |
LiveKit Cloud tiers (verified April 2026):
| Tier | Monthly base | Included agent minutes | Best for |
|---|---|---|---|
| Build | Free | 1,000 | Development and testing |
| Ship | $50 | 8,000 | Early production |
| Scale | $500 | Custom | Production scale, HIPAA |
| Enterprise | Custom | Custom | High-volume, compliance |
The livekit pricing model is fundamentally different from Vapi or Retell: you pay a small infrastructure fee ($0.01/min for the agent session) and then separately pay whatever your chosen model providers charge. There is no platform markup on inference. This is why the cost advantage at scale is real — but it also means your total cost depends entirely on the provider stack you build.
LiveKit vs Vapi vs Retell: choosing the right platform
The livekit vs vapi which is better 2026 question depends entirely on volume, technical depth, and how much control you want over the stack. The livekit vs retell comparison follows a similar logic — Retell is a flat-rate managed platform at $0.07+/min all-in, making it the fastest path to deployment, while LiveKit suits teams with engineering resources and volume above 10K minutes per month.
This livekit agents voice agent testing guide covers how to test a livekit voice agent before deployment — the five failure modes and the livekit voice agent testing checklist that gates every launch. For livekit testing methodology across all five dimensions, read on.
| Dimension | LiveKit Agents | Vapi | Retell AI |
|---|---|---|---|
| Model | Open source + managed cloud | Managed platform | Managed platform |
| Session cost | $0.01/min (+ provider costs) | $0.05/min (+ provider costs) | $0.07+/min (all-in) |
| Total real-world cost | $0.03–0.15/min | $0.15–0.33/min | $0.07+/min |
| Customisation | Full — any provider, any logic | BYOK with constraints | More opinionated |
| Technical complexity | High — you build the stack | Medium — config-driven | Low — integrated |
| Telephony | Native SIP (2025), Phone Numbers | Twilio, Telnyx, others | Built-in |
| Self-hosting | Yes — free | No | No |
| Built-in testing | Built-in test framework | Simulations (Alpha) | Limited |
| Best for | Technical teams, high volume | Quick developer setup | Fast deployment |
Choose LiveKit when: you have engineering resources to manage a self-assembled stack, volume above 10K minutes per month, full component control, or regulated industry requirements that mandate self-hosting.
Choose Vapi or Retell when: validating a concept, your team needs faster deployment, or you want a vendor to manage concurrency, scaling, and infrastructure.
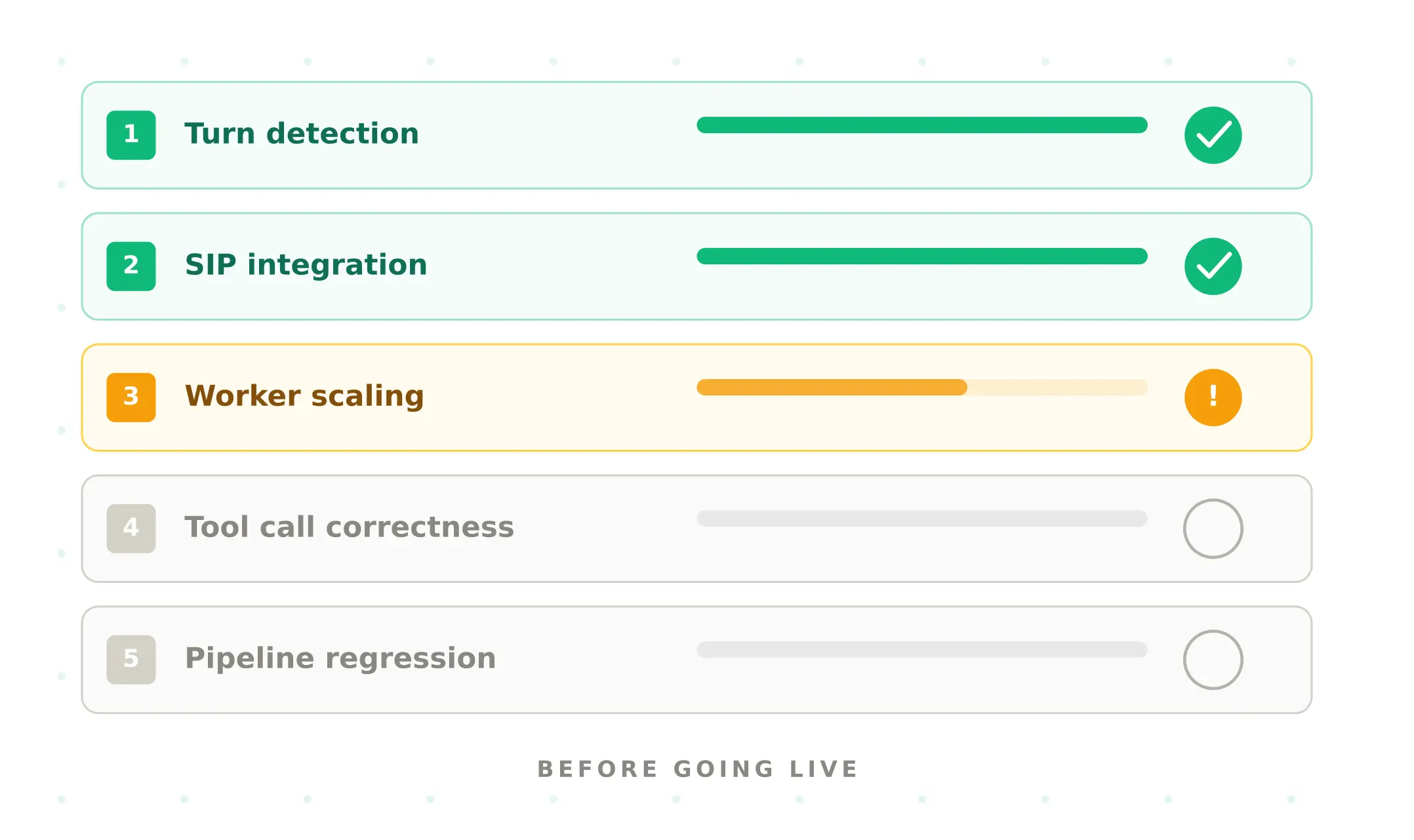
Five ways LiveKit voice agents fail before they reach users
1. Turn detection failures — does the agent know when to speak?
Turn detection is the hardest problem in conversational voice AI and the most common source of production failures in livekit voice agent deployments.
LiveKit Agents v1.5.x ships with two turn detection approaches. The default is semantic turn detection — a transformer model that predicts whether the user has finished their turn. The alternative is endpointing-based detection — silence detection with configurable thresholds. Both have specific failure modes:
Semantic turn detection excels when users complete full utterances but fails when they use filler words mid-sentence ("um, so I wanted to..."), restart sentences, or speak with significant pauses. At v1.5.x, the adaptive interruption handling model achieves 86% precision and 100% recall at 500ms overlap — meaning it catches all interruptions but generates some false positives from backchanneling ("mm-hmm", "right", "yeah"). In production, these false positives cause the agent to cut off mid-sentence when the user says "mm-hmm" affirmatively.
Silence-based endpointing fails in noisy environments — background noise fills the silence threshold and prevents the agent from detecting turn completion. A user calling from a busy office never signals end-of-turn clearly enough for the agent to respond.
The livekit turn detection failure production scenario most teams discover too late: the agent was tested in quiet conditions with complete utterances. In production, 40% of users have background noise above 55 dB and 30% use filler words that trigger premature turn completion.
The Evalgent angle: Evalgent's caller profiles configure speech pace, disfluency rate, interruption patterns, and background noise independently — systematically exposing which turn detection configuration breaks under which conditions before deployment. Run turn detection tests at three noise levels (45 dB, 65 dB, 75 dB) and three disfluency rates (clean, light filler, heavy filler) across your key scenarios. Document the breaking points before going live.
2. SIP integration gaps — does telephony work end-to-end?
LiveKit native SIP went GA in 2025. LiveKit Phone Numbers shipped alongside, enabling inbound and outbound calling without a Twilio bridge. This is one of the most significant recent changes to the platform — but the livekit sip integration introduces failure modes that WebRTC testing never catches.
PSTN codec behaviour. WebRTC uses Opus codec with 20ms packet intervals. PSTN telephony uses G.711 or G.722 with different acoustic characteristics. The codec transcoding step adds latency and introduces packet loss patterns that your STT model may not handle cleanly. An agent achieving sub-300ms TTFB on WebRTC may deliver 600–800ms TTFB under PSTN conditions due to transcoding overhead.
According to LiveKit's agents documentation, the framework supports SIP through LiveKit's telephony stack — which means livekit sip integration testing must cover the full PSTN path, not just the WebRTC playground. See the LiveKit Agents GitHub for code examples of SIP configuration patterns.
DTMF input. Users navigating legacy IVR menus press keypad digits. If your agent does not handle DTMF input explicitly, digit presses either produce silence or trigger unintended speech recognition events. Test keypad input explicitly across your call flows.
Call setup failures. SIP call setup introduces a negotiation phase before audio begins. Failed SIP INVITE responses, incorrect SDP negotiation, or misconfigured trunk credentials produce immediate call failure with no audio — a failure mode invisible to WebRTC testing. Test your SIP trunk configuration against your actual telephony provider (Telnyx, Twilio, or LiveKit Phone Numbers) with real phone calls before launch.
The Evalgent angle: Run your full scenario suite against your livekit sip integration using PSTN test calls — not just WebRTC connections in the agents playground. Track P95 TTFB separately for WebRTC and PSTN paths. Any scenario where the PSTN P95 exceeds 800ms is a reliability risk that will surface immediately at production volume.
3. Worker process scaling — does it hold up under concurrent load?
LiveKit Agents runs as worker processes that join rooms and handle agent logic. Each worker handles one or more concurrent sessions depending on your configuration and the computational cost of your pipeline. Worker scaling failures are the most common cause of production capacity incidents in self-assembled livekit voice agent stacks.
The failure mode is non-obvious in testing: with one or two concurrent callers, the worker pool handles load easily. At ten concurrent callers, workers reach CPU or memory limits. New calls queue or fail — not with a visible error, but with dead silence or connection timeouts. The first symptom is elevated call abandonment, not an error alert.
The livekit cloud managed deployment path handles worker orchestration automatically. Self-hosted deployments require explicit capacity planning — worker count, resource allocation, auto-scaling configuration, and queue behaviour when all workers are busy.
# Example: configuring worker capacity in LiveKit Agents
from livekit.agents import WorkerOptions, cli
def run_worker():
cli.run_app(
WorkerOptions(
entrypoint_fnc=entrypoint,
# Set explicit worker limit per process
worker_type=WorkerType.ROOM,
# Monitor via LiveKit's built-in observability
)
)The Evalgent angle: Synthetic caller load testing runs your LiveKit agent at 1×, 2×, and 5× expected peak concurrent volume before launch. For self-hosted deployments, pair this with system resource monitoring — CPU, memory, and worker queue depth — across the load test to identify the concurrency ceiling before users find it.
4. Tool call correctness — does the agent actually do what it says?
LiveKit Agents supports tool calling — functions your agent can invoke during a conversation. When the agent says "I've sent you a confirmation email," a tool call to your email service made that happen. When it says "Your appointment is confirmed for Thursday," a webhook to your booking system created the record.
As with all voice agent frameworks, transcript-based evaluation cannot verify tool call outcomes. The conversation can look perfect — correct phrasing, appropriate confirmation, high coherence score — while the tool call failed silently. This is especially common in self-assembled stacks where the tool call error handling logic is written by the team rather than managed by a platform.
LiveKit Agents v1.5.x includes per-turn latency metrics and session usage tracking by model and provider. These help with performance monitoring but do not verify downstream task completion — they tell you the tool call was invoked, not whether it succeeded in the downstream system.
# Tool call definition in LiveKit Agents
from livekit.agents import llm
@llm.ai_callable()
async def book_appointment(
date: str,
time: str,
customer_id: str
) -> str:
"""Book an appointment for the customer."""
# This must be tested for:
# 1. Correct parameter extraction under noisy speech
# 2. API success response handling
# 3. Graceful failure when API returns 500
# 4. What the agent says when the booking fails
result = await booking_api.create(date, time, customer_id)
return f"Booked for {date} at {time}"The Evalgent angle: Evalgent verifies tool call outcomes against downstream system state — not just whether the agent produced a confirmation sentence. For each scenario, define the expected tool call, expected parameters, and expected downstream state. Run the verification across your full scenario suite before launch, not as a spot-check.
5. Pipeline regression after every code change — does it still work after the last commit?
LiveKit Agents is code, not configuration. Every commit is a regression risk. A change to turn detection threshold, a tool definition update, a new system prompt, a plugin version bump, or a swap to a different STT provider can break behaviour that was working reliably.
This is fundamentally different from the regression risk in managed platforms like Vapi — where changes are typically configuration edits — because code changes affect the entire agent logic, not just prompt wording. A change to how your agent processes tool call results can produce silent failures across all scenarios that invoke that tool.
The regression testing approach — running a golden scenario suite after every change and requiring explicit pass before deployment — is the minimum viable gate for any production agent. Agents v1.5.x ships with a built-in test framework supporting LLM judges. Use it as your first layer, then run Evalgent's scenario suite as the production-fidelity gate.
For the specific case of model provider changes — switching STT from Deepgram to AssemblyAI, swapping TTS from Cartesia to ElevenLabs, updating your LLM from GPT-4o to a newer model — run a full regression suite against your golden call set before any provider switch reaches production. Response latency, turn detection behaviour, and tool call accuracy all change when the underlying model changes.
LiveKit Cloud vs self-hosted: what the testing implications are
The livekit self hosted vs livekit cloud decision affects not just cost but what you are responsible for testing.
LiveKit Cloud handles infrastructure, worker orchestration, scaling, observability, and SIP routing. Your testing responsibility is limited to agent behaviour — turn detection, tool calls, scenario coverage, and regression.
Self-hosted requires testing everything: the media server configuration, the SFU capacity under load, the network path to your telephony provider, worker process scaling, and the monitoring stack. Self-hosted deployments gain cost advantages at scale but require significantly more pre-production testing surface.
For teams starting out: test on Cloud. The infrastructure layer is managed, so evaluation effort focuses on agent behaviour rather than infrastructure reliability. Self-host only when volume justifies the engineering investment.
Pre-launch testing checklist for LiveKit voice agents
Complete every step before any LiveKit voice agent goes live:
1. Verify connectivity — confirm your LIVEKIT_URL, LIVEKIT_API_KEY, and LIVEKIT_API_SECRET are correctly configured. Test a worker process connecting to a room successfully.
2. Run full scenario suite — every designed flow, end-to-end. Flag any scenario with task completion below 90%.
3. Test turn detection across noise and disfluency profiles — run every scenario at 45 dB (quiet), 65 dB (open office), and 75 dB (street noise). Run with clean speech, light filler ("um", "uh"), and heavy filler. Document which combinations break your turn detection configuration.
4. Test SIP integration with real phone calls — if using LiveKit SIP or LiveKit Phone Numbers, call your agent from an actual phone. Measure P95 TTFB on PSTN separately from WebRTC. Test DTMF input if your flow uses keypad navigation.
5. Run concurrent load test — synthetic callers at 2× expected peak concurrent sessions. For self-hosted deployments, monitor CPU, memory, and worker queue depth throughout. Identify your capacity ceiling before users do.
6. Verify all tool calls against downstream state — for every function your agent can call, verify the downstream system receives the correct request, returns a success response, and the agent communicates the outcome correctly. Test 500 errors, timeouts, and missing parameters explicitly.
7. Run regression suite after final code change — do not deploy from an actively edited branch. Deploy from the commit whose scenario suite passed.
8. Establish P95 latency baseline — measure P50, P90, and P95 TTFB under PSTN conditions. If P95 exceeds 800ms, investigate before launch: codec transcoding overhead, STT provider latency, LLM TTFB, and TTS TTFB are the four levers.
Monitoring LiveKit agents in production
Once live, these metrics reveal LiveKit-specific production health:
Worker queue depth. For self-hosted deployments, monitor the number of sessions waiting for a worker. Queue depth above zero during peak hours is an early warning of capacity exhaustion. Set alerts at 50% of your configured worker limit.
Turn detection error rate. Monitor premature turn completions and missed turn completions. Both are visible in Cloud's built-in observability via transcripts and trace spans.
P95 TTFB by provider. LiveKit Agents v1.5.x ships with per-turn latency metrics by model and provider. Monitor STT, LLM, and TTS TTFB separately — a spike in one provider's P95 is invisible in the aggregate metric but immediately affects user experience.
Tool call failure rate. Track all non-success responses from your tool call endpoints. Any error rate above 1% is worth investigating before it compounds into user-facing failures.
Use Evalgent's production monitoring to correlate these LiveKit infrastructure signals with end-to-end task completion — connecting framework health metrics to the business outcomes that matter.
Summary
LiveKit Agents is the leading open source voice agent framework at v1.5.x. Test five things before launch: turn detection, SIP, worker scaling, tool calls, and code regression.
Frequently asked questions
What is LiveKit Agents and how does it work?
LiveKit Agents is an open-source Python and Node.js framework for building real-time voice AI agents. Worker processes join rooms and process audio through an STT-LLM-TTS pipeline. It reached v1.0 in April 2025 and runs v1.5.x as of April 2026 with adaptive interruption handling, semantic turn detection, and native MCP tool support. Supports 200+ model providers via plugins.
How much does LiveKit cost for voice agents?
Cloud charges $0.01/min for agent session minutes plus separate inference costs for your STT, LLM, and TTS providers. Build tier is free with 1,000 agent session minutes monthly. Ship is $50/month. Scale is $500/month with HIPAA compliance. Total real-world cost runs $0.03–0.15/min — 60–80% cheaper than managed platforms above 10,000 minutes per month.
How does LiveKit compare to Vapi?
The framework is open-source infrastructure — you build and manage the stack. Vapi is a managed platform. Agent sessions cost $0.01/min versus Vapi's $0.05/min, with total costs $0.03–0.15/min versus $0.15–0.33/min. The livekit vs vapi decision is primarily a volume and engineering capacity question — LiveKit at scale, Vapi for faster deployment.
What is LiveKit turn detection and why does it fail in production?
The Agents framework uses semantic turn detection — a transformer model predicting whether a user has finished speaking — and endpointing-based silence detection. Semantic turn detection at v1.5.x achieves 86% precision and 100% recall at 500ms overlap, generating false positives from backchanneling. In production, users saying "mm-hmm" mid-agent-speech trigger premature cutoffs. Test across noise levels and disfluency rates before deployment.
What is the difference between LiveKit Cloud and self-hosted LiveKit?
The livekit self hosted vs livekit cloud choice: Cloud is a managed service handling infrastructure, orchestration, scaling, and observability — pay per usage, starting free. Self-hosted runs the open-source server on your own infrastructure, eliminating per-minute fees. Self-hosting pays off above roughly 5M minutes per month but requires testing the infrastructure layer as well as agent behaviour.
How do I test LiveKit SIP integration before going live?
Test your livekit sip integration using real phone calls from an actual PSTN number — not WebRTC connections in the agents playground. Measure P95 TTFB separately for PSTN and WebRTC (PSTN typically adds 200–500ms from codec transcoding). Test DTMF keypad input explicitly. Test with your actual telephony provider — Telnyx, Twilio, or Phone Numbers — not a simulated SIP trunk.
What breaks in LiveKit voice agents in production?
The most common voice agent production failures on this platform are: turn detection false positives from backchanneling causing mid-sentence cutoffs; SIP PSTN latency exceeding sub-300ms TTFB targets; worker process capacity exhaustion during peak concurrent load; tool call silent failures where the agent confirms a task the downstream system never received; and pipeline regressions from code changes that broke a previously working scenario.
Does LiveKit have built-in testing tools?
Yes. The Agents SDK ships with a built-in test framework supporting scenario tests with LLM judges — the starting point for any livekit voice agent testing checklist. LiveKit Cloud provides transcripts, trace spans, and per-turn latency metrics. These cover unit testing and monitoring. Systematic pre-launch evaluation across realistic user behaviour requires an external evaluation layer like Evalgent.
Related Articles
Conversational AI testing: the complete voice agent stress testing guide
Systematic conversational ai testing for voice agents. Find breaking points across noise, accents, interruptions, and latency before real users do.
Read more
ElevenLabs voice agent testing guide: what to check before going live
Test your ElevenLabs voice agent before going live. Covers scenario gaps, user behaviour, tool calls, concurrent limits, and voice quality regression.
Read more