Test your voice agent
Deepgram STT testing guide for voice agents: what the benchmarks don't tell you
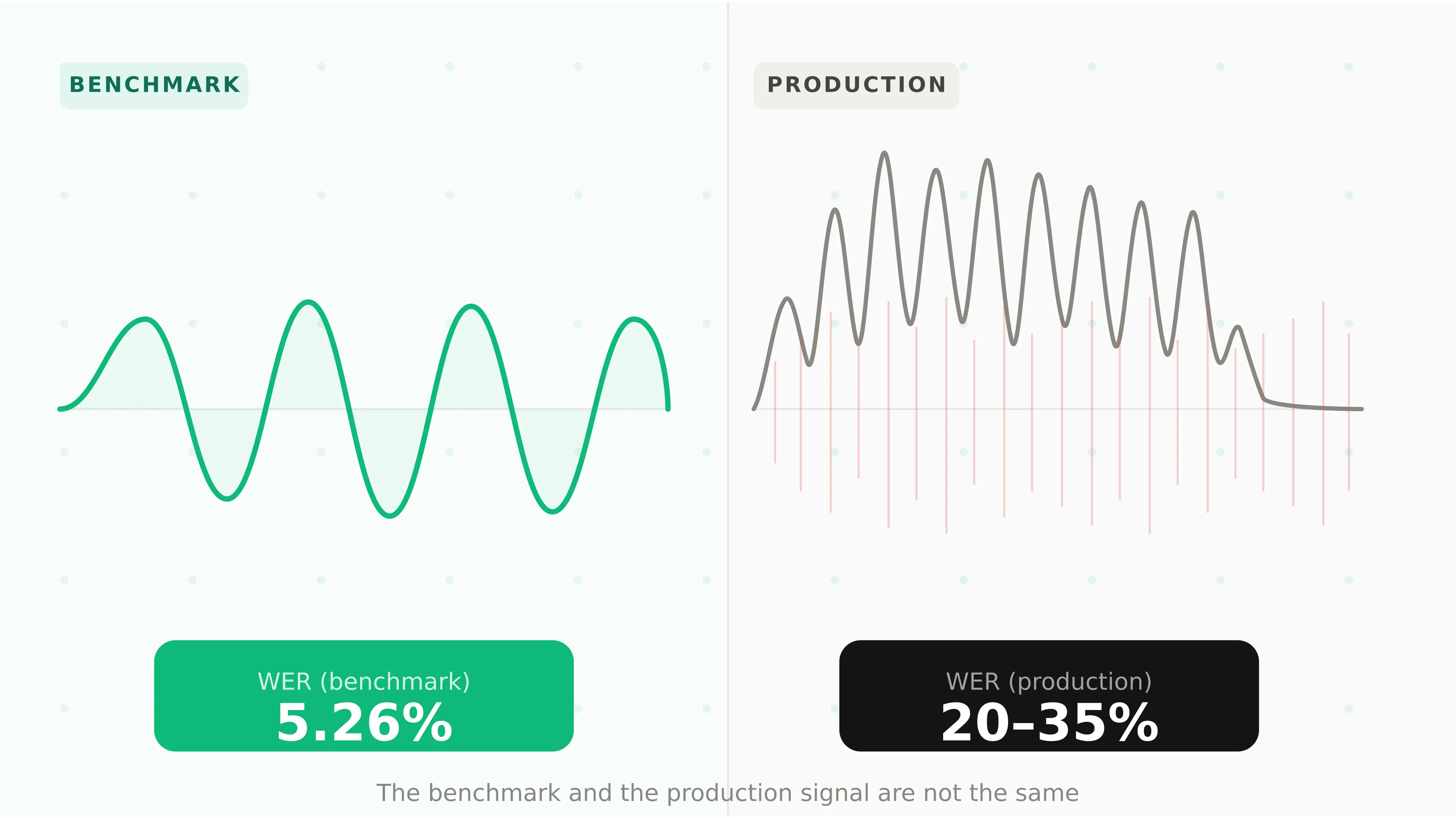
Deepgram Nova-3 is the default STT choice for developers building voice agents on Vapi, Retell, LiveKit, and Pipecat. Its headline numbers are compelling: 5.26% WER on clean audio, sub-300ms deepgram streaming latency, a 53.4% reduction in word error rate versus competitors on streaming benchmarks, and $0.0077/min — making it both the fastest and cheapest speech to text api at scale.
As a voice recognition api it excels at real-time conversational ai speech recognition. The deepgram nova 3 model is the version most production voice agents use today. The Deepgram model documentation covers all available models and options.
The problem is not with the numbers. The problem is what they are measuring.
Deepgram's 5.26% WER comes from clean audio benchmarks. Voice agents do not run on clean audio. They run on calls from open-plan offices, moving vehicles, and factory floors. They handle speakers with regional accents, fast speech, false starts, and overlapping noise. They serve users who interrupt, restart sentences, and say "um, actually, wait" mid-phrase.
In those conditions, the benchmark number and the production number diverge significantly. This guide covers what to test in your Deepgram STT integration before that divergence starts costing you users.
What Deepgram actually is in 2026
This deepgram review covers the full product range — not just the STT API most developers know.
Deepgram Nova-3 is the flagship STT model, released in early 2025. It delivers 5.26% WER (Deepgram internal) and 12.8% WER on third-party Artificial Analysis benchmarks using Common Voice v16.1. The gap is the first lesson about Deepgram in production: internal benchmarks use curated audio; third-party benchmarks use diverse real-world speech. Both are valid — they measure different things.
Deepgram Flux is a conversational STT model built specifically for voice agents. Unlike Nova-3, Flux understands conversational flow — with model-integrated end-of-turn detection, configurable turn-taking dynamics, and ultra-low latency for voice agent pipelines. Flux Multilingual extends this to 10 languages.
Deepgram Aura-2 is the TTS product — sub-200ms latency with entity-aware processing for addresses, phone numbers, and alphanumeric identifiers.
Deepgram Voice Agent API bundles STT, LLM, and TTS at $4.50/hr — eliminating the multi-provider billing complexity of BYOK stacks like Vapi.
| Product | Primary use | Key metric |
|---|---|---|
| Nova-3 | STT for voice agents | 5.26% WER (internal), sub-300ms |
| Flux | Conversational STT | End-of-turn detection built-in |
| Flux Multilingual | Multi-language STT | 10 languages |
| Nova-3 Medical | Healthcare STT | Clinical/pharmaceutical vocabulary |
| Aura-2 | TTS | sub-200ms latency |
| Voice Agent API | Full bundled stack | $4.50/hr all-in |
Deepgram pricing: what you actually pay
According to Deepgram's pricing page, the deepgram pricing structure is usage-based with two tiers:
| Plan | Streaming | Batch |
|---|---|---|
| Pay-as-you-go | $0.0077/min ($4.62/hr) | $0.0043/min ($0.258/hr) |
| Growth (annual) | $0.0065/min ($3.90/hr) | Lower rates |
At $4.30 per 1,000 minutes, Deepgram Nova-3 is the cheapest major speech to text api — significantly below OpenAI's GPT-4o Transcribe at $6.00 per 1,000 minutes and Google Chirp 2 at $16.00 per 1,000 minutes. New accounts receive $200 in free credits.
For the deepgram vs whisper for voice agents comparison: Nova-3 ($0.0077/min) versus Whisper Large V3 Turbo ($6.00/1,000 min) — Deepgram is approximately 3× cheaper. Deepgram Nova-3 scores 12.8% WER versus GPT-4o Transcribe at 8.9% WER on the same Artificial Analysis benchmark — Whisper-class models are more accurate on third-party benchmarks, but Deepgram's latency advantage (sub-300ms versus Whisper's higher TTFB) is decisive for real-time voice agents where every millisecond affects conversation quality.
The deepgram asr api billing is per-second, not rounded up to the nearest minute or 15-second block — making it meaningfully cheaper than AWS Transcribe (15-second minimum) for short conversational utterances.
Five ways Deepgram STT fails voice agents in production
1. Noise degradation — clean audio WER does not predict production WER
This is the most important and least discussed failure mode in Deepgram STT deployments.
Nova-3 achieves 5.26% WER on clean audio and maintains below 15% WER in noisy environments — a strong result relative to competitors. But benchmark noisy conditions and production noisy conditions are different.
A benchmark noisy condition is controlled: a specific dB level, a specific noise type, a specific speaker. Production noise is variable: a user calling from a street corner where traffic spikes to 85dB mid-sentence, or on a hands-free phone in a car where road noise creates a constant low-frequency hum.
The deepgram noise sensitivity voice agent failure pattern: the agent works perfectly in testing. In production, 15–20% of users call from conditions outside test coverage. For those users, WER climbs from 5% to 20–35%. Intent classification degrades. Tool calls receive wrong parameters. The task fails — and the user doesn't know why.
The Evalgent angle: Evalgent's acoustic stress testing runs your full scenario suite across synthetic callers configured with 8 noise profiles — from quiet office (45dB) through street traffic (75dB) and factory floor (85dB). The output is not a single WER number but a degradation curve: at what noise level does task completion rate drop below your acceptable threshold? That is the number your deployment decision should be based on, not the benchmark WER.
2. Accent accuracy — Nova-3 is strong but not uniform across all accents
Nova-3 supports 45+ languages and demonstrates superior performance across the seven languages in Deepgram's multilingual testing — including up to 8:1 preference ratios in certain languages versus competitors. For English, it supports multiple regional variants.
But WER uniformity across accents is not the same as accuracy uniformity. Nova-3's training data, like all commercial STT models, reflects the distribution of data available at training time. US English is the dominant training distribution. Regional accents — Scottish, Indian, Nigerian, South African, Southern US — vary in how well they are covered, and that variation is not visible in aggregate WER benchmarks.
For voice agents serving a geographically diverse user base, accent accuracy is not an edge case — it is a core reliability requirement. A healthcare voice agent deployed in the UK that cannot reliably transcribe Scottish English will generate task failures for a measurable fraction of its users. Those users are the ones who most need reliable service and are least likely to repeat themselves or tolerate failure.
The Evalgent angle: Evalgent's caller profiles include accent configuration as one of the eight behavioural parameters per synthetic caller. Run your full scenario suite across at minimum three accent profiles representative of your actual user base — not just the accent of whoever built the agent. Track task completion rate separately per accent profile. Any accent that drops more than 10 percentage points below your clean-audio baseline is a production risk that needs investigation before launch.
3. Disfluency handling — real users don't speak like benchmark audio
Benchmark audio is clean: complete sentences, no false starts, no filler words. Real users are not.
Real users say "um" and "uh" mid-phrase. They start a sentence, change their mind: "I want to book — actually, can I change my existing appointment?" They trail off and restart. They speak in fragments: "Thursday. 2pm. The dentist one."
How Deepgram handles disfluency has two components. First, whether the transcript is accurate despite disfluency. Second, whether that transcript is clean enough for LLM intent classification — or whether disfluency confuses what the user actually wanted.
Deepgram's smart formatting processes filler words — but false starts and mid-sentence restarts in streaming mode introduce a specific failure: partial transcripts arrive at the LLM while the user is still mid-correction, potentially triggering a tool call based on the first half of a sentence the user was abandoning.
The Evalgent angle: Synthetic caller testing with configurable disfluency rate exposes this failure mode systematically. Run every scenario at three disfluency levels: clean speech, light filler (occasional "um", "uh"), and heavy disfluency (false starts, restarts, corrections). Track whether LLM intent classification and tool call accuracy degrade as disfluency increases — and at what disfluency threshold the failure rate becomes production-unacceptable.
4. Streaming latency under concurrent load — P95 is where the story changes
Deepgram Nova-3 delivers sub-300ms transcription latency under standard conditions. That number is real and consistent under low-to-moderate concurrent load. The problem is P95.
At low concurrent call volume — one to five simultaneous streams — Deepgram's infrastructure handles load easily. P50 and P95 are close. At production concurrent volumes — dozens or hundreds of simultaneous streams — P95 latency diverges from P50. The average looks fine. The worst 5% of calls experience 600ms+ STT latency.
For voice agents, this matters because contact centres see 8–12% call dropout above 600ms total conversation latency. A single STT response at 600ms does not exceed that threshold — but combined with LLM inference time and TTS latency, a 600ms STT spike pushes total TTFB above 1,000ms. Users experience an awkward pause. A non-trivial fraction hang up. Those who call back add to concurrent load, compounding the problem.
The deepgram streaming latency voice agents failure pattern is self-reinforcing at peak: latency spikes → call abandonment → callbacks → higher concurrent load → further latency spikes.
# Measuring Deepgram streaming latency at P50 and P95
import deepgram
import numpy as np
import time
latencies = []
async def stream_and_measure(audio_chunk):
start = time.perf_counter()
async with deepgram.listen.asyncwebsocket.v("1") as connection:
# Send audio and capture time-to-first-transcript
await connection.send(audio_chunk)
async for result in connection:
if result.channel.alternatives[0].transcript:
latencies.append(time.perf_counter() - start)
break
# After test run:
p50 = np.percentile(latencies, 50)
p95 = np.percentile(latencies, 95)
print(f"P50: {p50*1000:.0f}ms P95: {p95*1000:.0f}ms")
# P95 > 500ms under load is a red flag for voice agentsThe Evalgent angle: Load testing with synthetic callers at 1×, 2×, and 5× expected peak concurrent volume reveals the P95 latency ceiling before real users find it. Monitor P95 separately from average — a flat average with rising P95 is the exact signature of an approaching capacity issue.
5. STT error compounding — how one misheard word cascades through the pipeline
This is the failure mode that makes STT errors in voice agents more expensive than STT errors in transcription tools.
In a transcription tool, a word error rate of 5% means 5% of words are wrong. A human reviewer catches and corrects them. The error is contained.
In a voice agent, a word error is not contained. It flows downstream:
1. STT misheard "fifty" as "fifteen" — a single substitution error
2. LLM receives "fifteen" in the transcript and generates a confirmation: "I'll transfer fifteen pounds"
3. Tool call fires with `amount: 15` instead of `amount: 50`
4. Downstream system processes the wrong amount
5. Agent confirms success: "Done — I've transferred fifteen pounds"
6. User heard "fifty" — they have no reason to correct the agent
7. The error surfaces in the next billing cycle
LLM-as-judge transcript evaluation cannot detect this failure. The transcript shows a coherent, appropriate interaction. The score is high. The task failed. This is how stt errors affect voice agent reliability in ways that standard evaluation metrics completely miss.
The compounding is non-linear: a 5% word error rate does not produce a 5% task failure rate. It produces a task failure rate that depends on which words are wrong. "Fifty" and "fifteen" are a single substitution. In a financial context, that substitution has a 100% task failure rate for the affected call.
The Evalgent angle: Evalgent verifies tool call outcomes against downstream system state — not transcript quality. For scenarios involving numerical values, dates, names, or location data — the categories most vulnerable to STT substitution errors — Evalgent checks whether what the downstream system received matches what the user actually said. This is the only evaluation method that catches STT error compounding before production. Run these verification checks across all noise and accent profiles, not just clean audio.
Deepgram vs Whisper vs AssemblyAI: which STT for voice agents
For teams selecting a speech to text api rather than testing an existing integration, here is how the three leading options compare across the dimensions that matter for voice agents in production:
| Dimension | Deepgram Nova-3 | OpenAI Whisper / GPT-4o Transcribe | AssemblyAI |
|---|---|---|---|
| WER (Artificial Analysis) | 12.8% | 8.9% (GPT-4o Transcribe) | Competitive |
| Streaming latency | sub-300ms | Higher | Competitive |
| Pricing per 1,000 min | $4.30 | $6.00 | Competitive |
| Real-time streaming | Native | Limited (Whisper batch-first) | Yes |
| Conversational STT | Flux model | No | No |
| End-of-turn detection | Flux (built-in) | External VAD | External VAD |
| Noise robustness | Strong | Strong | Strong |
| Languages | 45+ (Nova-3) | 50+ | 99+ |
| Self-hosting | Yes | Whisper open-source | No |
| Best for | Real-time voice agents | Accuracy-first, batch | Broad language coverage |
Deepgram Nova-3 is the right choice when streaming latency is the priority — real-time voice agents where TTFB directly affects conversation quality. GPT-4o Transcribe is the right choice when accuracy is the priority over latency — post-call analytics, transcription, and use cases where a 200–300ms latency advantage matters less than the 3.9pp WER improvement. AssemblyAI is the right choice for deployments needing 99+ language support.
For voice agents specifically: Deepgram's Flux model with built-in end-of-turn detection eliminates the external VAD layer required by Whisper-based stacks — reducing integration complexity and the associated failure surface.
Pre-launch testing checklist for Deepgram STT integrations
Complete every step before any voice agent using Deepgram STT goes live:
1. Verify API connectivity and model selection — confirm your Deepgram API key, model (nova-3 or flux), and streaming configuration. Test a live audio stream and verify transcripts return within expected latency.
2. Establish clean audio baseline — run your full scenario suite with clean audio and document task completion rate, word accuracy on key terms, and streaming P50/P95 latency. This is your reference point for all subsequent tests.
3. Test noise degradation — run every scenario at 45dB, 65dB, and 75dB noise profiles. Track task completion rate per noise level. Flag any scenario where completion drops more than 10pp from the clean baseline.
4. Test accent coverage — run at minimum three accent profiles representative of your actual user base. Track intent classification accuracy and tool call parameter correctness per accent. Accent failures are often invisible in aggregate metrics.
5. Test disfluency handling — run every scenario at clean, light filler, and heavy disfluency levels. Track whether LLM intent classification degrades with disfluency — not just whether Deepgram produces a transcript, but whether the transcript enables correct task completion.
6. Run P95 latency test under concurrent load — run synthetic callers at 2× and 5× expected peak concurrent streams. Measure P50 and P95 STT latency separately. If P95 exceeds 500ms, investigate before launch.
7. Verify tool call correctness for STT-sensitive parameters — for every scenario involving amounts, dates, names, or locations, verify that downstream systems receive what the user said — not what a clean transcript assumed they said. Run these across all noise and accent profiles.
8. Establish production monitoring baselines — before launch, document your P50/P95 STT latency, task completion rate, and repeat contact rate. These are your production health references. Any metric that moves more than 10% post-launch warrants investigation.
Monitoring Deepgram in production
Once live, these metrics reveal Deepgram-specific production health:
STT latency at P95. Monitor separately from P50. A rising P95 while P50 stays flat is the earliest signal of concurrent load pressure on Deepgram's infrastructure. Set alerts when P95 exceeds 450ms — this gives time to investigate before user experience degrades.
Intent classification accuracy by noise category. If you can tag calls by acoustic environment (clean, moderate noise, high noise), track task completion rate per category. A declining completion rate in high-noise calls is a Deepgram STT signal, not an LLM signal.
Tool call parameter error rate. Track calls where tool call parameters do not match what the user stated. This is the downstream signal for STT substitution errors — especially on numerical values and proper nouns that are common STT misrecognition targets.
Deepgram API error rate. Monitor 429 (rate limit) and 5xx responses. Any elevated error rate requires immediate attention — a failed STT request means no transcript, which means the agent cannot respond.
Use Evalgent's production monitoring to correlate Deepgram STT signals with end-to-end task completion outcomes — connecting the STT layer to the business results that matter.
Summary
Deepgram Nova-3 is the leading speech to text api for real-time voice agents. Test five things: noise degradation, accent accuracy, disfluency, P95 latency, and STT error compounding.
Frequently asked questions
What is Deepgram Nova-3 and how accurate is it?
Deepgram Nova-3 is the flagship STT model, released in early 2025. It achieves 5.26% WER on Deepgram's internal benchmarks and 12.8% WER on third-party Artificial Analysis benchmarks using Common Voice v16.1. The gap reflects curated versus real-world audio. Sub-300ms streaming latency and $0.0077/min pricing make it the standard speech to text api for voice agents.
How does Deepgram pricing work?
Deepgram charges per second of audio — $0.0077/min streaming or $0.0043/min batch on Pay-as-you-go. The Growth plan reduces streaming to $0.0065/min. At $4.30 per 1,000 minutes, the deepgram asr api is cheaper than OpenAI GPT-4o Transcribe ($6.00) and Google Chirp 2 ($16.00). New accounts receive $200 in free credits.
How does Deepgram compare to Whisper for voice agents?
Nova-3 delivers sub-300ms streaming latency versus Whisper's higher TTFB — decisive for real-time conversation. GPT-4o Transcribe scores 8.9% WER versus Nova-3's 12.8% on Artificial Analysis benchmarks — Whisper-class models are more accurate. The deepgram vs whisper for voice agents choice: Deepgram for real-time agents, GPT-4o Transcribe for accuracy-first batch applications.
What is Deepgram Flux and how is it different from Nova-3?
Deepgram Flux is a conversational STT model built specifically for voice agents. Unlike Nova-3, which transcribes speech, Flux includes model-integrated end-of-turn detection and configurable turn-taking dynamics — eliminating the external VAD layer required by standard STT integrations. Flux Multilingual extends this to 10 languages. For voice agents, Flux reduces integration complexity and the failure surface associated with external VAD misconfigurations.
What breaks in Deepgram STT in production?
The most common deepgram stt production failures are: noise degradation pushing WER from 5% to 20–35% in real conditions; accent coverage gaps producing elevated error rates; disfluency handling confusing LLM intent classification; P95 streaming latency spikes under concurrent load; and STT error compounding where a single word substitution produces wrong tool call parameters and a failed task.
How do STT errors affect voice agent reliability?
STT errors compound through the pipeline. A single substitution — "fifty" misheard as "fifteen" — produces a correct-looking transcript, triggers a coherent LLM response, fires a tool call with wrong parameters, and fails the task silently. This is how stt errors affect voice agent reliability in ways transcript evaluation misses. Verifying tool call outcomes against downstream system state is the only reliable method for catching this.
What is the difference between Deepgram Nova-3 WER on internal vs third-party benchmarks?
This deepgram nova 3 review 2026 finding matters: internal deepgram wer production accuracy shows 5.26%, while Artificial Analysis scores Nova-3 at 12.8% using Common Voice v16.1. Both are accurate — they measure different audio distributions. Internal benchmarks use curated audio. Third-party benchmarks use diverse real-world speech. The 12.8% is closer to production reality.
How do I test my Deepgram STT integration before going live?
Here is how to test deepgram stt for voice agents before deployment: verify API connectivity; establish a clean audio baseline; test noise degradation at 45dB, 65dB, and 75dB; test accent coverage; test disfluency at clean, light, and heavy levels; run P95 latency under concurrent load; verify tool call parameter correctness; and document production monitoring baselines before launch.
Related Articles
Conversational AI testing: the complete voice agent stress testing guide
Systematic conversational ai testing for voice agents. Find breaking points across noise, accents, interruptions, and latency before real users do.
Read more
ElevenLabs voice agent testing guide: what to check before going live
Test your ElevenLabs voice agent before going live. Covers scenario gaps, user behaviour, tool calls, concurrent limits, and voice quality regression.
Read more