Test your voice agent
How to test speech-to-speech voice agents
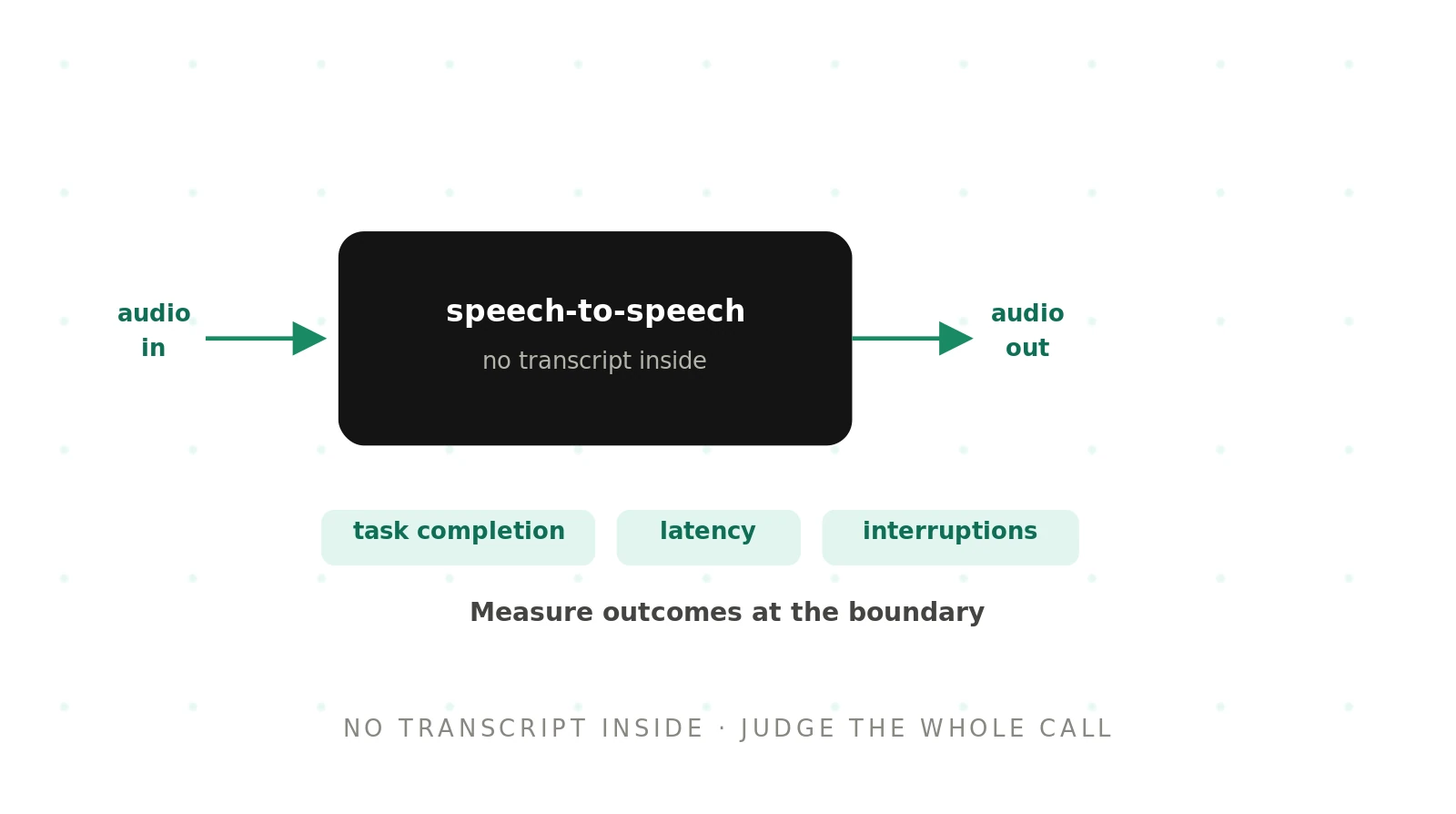
Speech-to-speech models are a leap forward for latency and naturalness. They are also a step backward for visibility. A cascading agent shows you a transcript at every stage; a speech-to-speech agent shows you nothing in the middle. That black box changes how you have to test. This guide explains why testing speech-to-speech voice agents is different, and how to do it well.
Evalgent evaluates the whole call, which is exactly what a black-box model requires. That focus on outcomes is the key to testing these agents well. First, the core problem.
Why speech-to-speech agents are harder to test
A cascading agent is transparent. Its speech-to-text stage produces a transcript, its LLM produces a response, and its text-to-speech stage produces audio. When a call fails, you can see which stage broke. Our cascading vs speech-to-speech guide covers that contrast in full.
A speech-to-speech agent removes the middle. Audio goes in and audio comes out through one model, with no explicit transcript between. This is the architecture behind offerings like xAI's Grok Voice, described on the xAI Voice page. It is faster, but it is a black box. You cannot open it to see why a call went wrong, which is what makes black-box voice agent testing the defining challenge.
What you can and cannot measure
The lost transcript takes specific measurements with it. Knowing which ones disappear tells you what to test instead.
- You lose per-stage metrics: no mid-pipeline transcript means no isolated STT or LLM measurement.
- You can still measure the audio in and out: the caller's speech and the agent's speech are observable.
- You can measure outcomes: did the task complete, did the agent follow policy, did it escalate correctly.
- You can measure timing: latency and turn-taking are observable at the boundary.
So the shift is from inspecting internals to judging behaviour. You test what the caller experiences, not what the model does inside. That is the heart of outcome-based evaluation.
Can you measure WER on a speech-to-speech agent?
Not directly, and this surprises teams. Word error rate needs a transcript to compare against a reference, and a speech-to-speech model does not expose one. There is no internal ASR output to score, so the usual speech recognition accuracy metric does not apply the same way.
You can approximate it. Transcribe the caller's audio and the agent's audio with a separate model, then reason about whether the agent understood correctly. But that is an external check, not a look inside. For a speech-to-speech agent, the honest signal is whether the agent acted correctly, not what it transcribed, because it never transcribed anything you can see.
Outcome-based testing: the reliable approach
If you cannot see inside, judge the outside. Outcome-based testing runs realistic calls and scores what happened: did the caller reach their goal, did the agent stay on policy, did it handle the interruption. This works regardless of architecture, which is why it is the right foundation for testing speech-to-speech voice agents.
The method is simple to state. Drive the agent through real scenarios. Measure task completion, adherence, and latency. Compare against thresholds. Because the score is based on behaviour, the black box does not matter; you are grading the call, not the internals. Our ai voice agent testing pillar covers this discipline in depth.
Metrics that work without a transcript
You need metrics that live at the call boundary, not inside the model. These carry the evaluation.
- Task completion: did the caller achieve their goal? The primary outcome.
- Instruction adherence: did the agent follow policy and required steps?
- Latency: time to respond, a speech-to-speech strength worth verifying.
- Interruption recovery: did barge-in work, and did the agent yield cleanly?
- Escalation accuracy: did it hand off to a human when it should?
- Per-cohort splits: did it hold up across accents and noise?
Notice none of these needs an internal transcript. They are all observable directly from the call itself. Be cautious using an LLM as a judge to grade the audio, since it evaluates language, not the full interaction.
Testing turn-taking and interruptions
Speech-to-speech models are sold on natural turn-taking, so that is exactly what you must test. Their low latency makes interruptions feel smooth, but smooth is a claim to verify, not assume.
Drive calls that interrupt the agent mid-response and check that it stops and listens. Test backchannels, so a caller saying "mm-hm" does not make it halt. Test rapid back-and-forth and overlapping speech. Turn-taking is invisible to any transcript-based check, so it can only be judged by listening to the call, which suits the outcome-based approach a speech-to-speech agent forces on you anyway.
Building the test set and handling model updates
The test set is the same discipline as any voice agent, run against a black box. Reproduce your real callers: accents, background noise, domain vocabulary, and off-script behaviour, through your actual telephony. Then measure per cohort so a failing group is not hidden by an average. Use synthetic callers to run the volume you need.
Regression matters more here, not less. A speech-to-speech model updates as one unit, so a new version can change behaviour you relied on, with no per-stage transcript to localise the change. Re-run the full outcome-based suite on every model update and compare against the last known-good run. Pair this with production monitoring, as covered in voice agent observability.
Terminology and why the shift is real
The category has several names. Speech-to-speech. Realtime. Single-model. When teams say sts voice agent testing, they mean the same challenge: a model you cannot open.
That naming matters, because it changes the tooling you reach for. To test speech-to-speech agents, you cannot reuse a transcript-first harness. Speech-to-speech evaluation has to start from audio and outcomes. To evaluate realtime voice agents well, the harness must drive real calls, listen to the responses, and score the result.
This is a genuine shift in practice. For years, voice testing leaned on the transcript. You compared what the model heard to a reference, and you were mostly done. A real-time single model breaks that habit. There is no reference transcript to compare against, because the model never produced one you can read.
So the discipline moves up a level. Instead of grading the words, you grade the call. Did the agent do the right thing? Did the caller leave satisfied? Those questions were always the point. The black box just removes the shortcut of checking the transcript.
The upside is that outcome-based scores are more honest anyway. A transcript can be perfect while the call fails. Grading the outcome cannot be fooled that way. So the constraint a speech-to-speech model imposes nudges you toward better testing, not worse.
One more practical point. Because you cannot localise a failure to a stage, error analysis leans harder on the recording. When a call goes wrong, you listen to it. You note what the caller said and how the agent responded. Then you turn that into a new test scenario. Keep every failed call, tag it, and feed it back into the suite. Over time that library of real failures becomes your most valuable test set.
Testing speech-to-speech agents with Evalgent
Evalgent is built to evaluate the whole call, which is exactly what a black-box model needs. It never depends on an internal transcript. Scenarios drive the agent through realistic calls, including interruptions and edge cases. Profiles vary caller accents and behaviour so results split per cohort. Metrics score task completion, latency, adherence, and interruption recovery with custom thresholds. Evaluations run this as automated batches of synthetic callers, and Reviews let your team hear exactly where the agent struggled.
The result is a trustworthy verdict on an agent you cannot see inside. You measure what the caller experiences, which is the only thing a speech-to-speech model lets you measure anyway. Whatever the architecture, outcome-based full-call testing tells you whether it is ready.
Frequently asked questions
How do you test a speech-to-speech voice agent?
Test a speech-to-speech voice agent with outcome-based, full-call testing, because it has no intermediate transcript to inspect. Run realistic calls with accents, noise, and interruptions, and measure task completion, adherence, latency, and interruption recovery per cohort. Since you cannot see inside the model, you judge what the caller experiences. Synthetic callers make this repeatable at volume before launch.
Why are speech-to-speech agents harder to test?
Speech-to-speech agents are harder to test because they are a black box. A cascading pipeline exposes a transcript at each stage, so you can see whether transcription, reasoning, or speech failed. A speech-to-speech model takes audio in and emits audio out with no explicit transcript between, so you cannot isolate an internal stage. You can only judge the outcome of the whole call.
Can you measure WER on a speech-to-speech agent?
Not directly. Word error rate needs an internal transcript to compare against a reference, and a speech-to-speech model does not expose one. You can approximate understanding by transcribing the audio with a separate model, but that is an external check, not a look inside. For these agents, whether the agent acted correctly is a more honest signal than a transcript score.
What metrics matter for speech-to-speech testing?
The metrics that matter for speech-to-speech testing live at the call boundary: task completion, instruction adherence, latency, interruption recovery, and escalation accuracy, all split per cohort. None of these needs an internal transcript, so they work on a black-box model. Task completion is usually the primary outcome, with latency and interruption handling verifying the architecture's promised strengths.
How do you evaluate a realtime voice agent?
Evaluate a realtime voice agent, which is another name for speech-to-speech, with outcome-based testing on realistic calls. Measure whether the caller's goal was met, whether the agent followed policy, and how it handled interruptions and latency, per cohort. Because a realtime model has no per-stage visibility, the evaluation must judge behaviour, not internals. Run it before launch and after every model update.
Do speech-to-speech agents need more testing?
Yes, arguably more than cascading agents. A speech-to-speech model is newer, updates as one unit, and offers no per-stage transcript to localise a problem, so failures are harder to diagnose after the fact. That makes thorough pre-release, outcome-based testing more important, not less. You compensate for reduced visibility inside the model with stronger evaluation of the whole call.
How do you test turn-taking in a speech-to-speech agent?
Test turn-taking by driving calls that interrupt the agent mid-response and checking that it stops and listens. Include backchannels like "mm-hm" that should not make it halt, plus rapid back-and-forth and overlapping speech. Turn-taking cannot be judged from a transcript, so you evaluate it by listening to the call, which fits the outcome-based approach a speech-to-speech model requires.
Outcome-based vs per-stage testing: what is the difference?
Per-stage testing inspects each component of a cascading pipeline, using the transcript at every step. Outcome-based testing judges the whole call by what the caller experienced, regardless of internals. Cascading agents allow both; speech-to-speech agents, being a black box, allow only outcome-based testing. Outcome-based evaluation works for any architecture, which is why it is the safest foundation.
Conclusion
Testing speech-to-speech voice agents means giving up the per-stage transcript and judging the call by its outcome. You cannot see inside the model, so you measure what the caller experiences: task completion, adherence, latency, and interruption handling, per cohort.
The black box is not a reason to test less. It is a reason to test the whole call harder, because outcomes are the only signal a speech-to-speech agent gives you, and callers judge on outcomes too.
Related Articles

How to automate voice agent testing: synthetic callers vs manual QA
Learn how ai test automation replaces manual QA for voice agents. Compare synthetic callers vs human testers, with a 5-step framework to scale without hiring.
Read more
AI Agent Testing vs Voice Agent Testing: What General Tools Miss for Voice
AI agent testing measures text outputs. Voice agent testing measures behaviour through an acoustic pipeline. Five failure categories general tools miss.
Read more