Test your voice agent
Self-improving voice agents: how feedback loops make agents better
Most voice agents ship and then stay frozen until someone manually fixes them. Self-improving voice agents close that gap with a loop: every call becomes data, and that data drives the next improvement. This guide explains how the loop works, whether it needs retraining, the risks, and why evaluation is the part that makes it safe.
Evalgent has a direct stake here, because the feedback signal that drives improvement is measurement. We return to that. First, the concept.
What is a self-improving voice agent?
Self-improving voice agent: a voice agent that uses production feedback to get better over time, updating its prompts, knowledge, or model through a repeating loop rather than a single training pass.
A traditional agent is static after launch. A self-improving agent treats every interaction as a learning signal. It reviews what happened, identifies where it failed, and feeds that back into the next version. Self-learning voice agents apply this idea continuously, so performance trends up instead of staying flat.
This is less about a single clever model and more about a process. Continuous learning voice ai is a system that observes itself, learns from real calls, and improves. The model matters, but the loop is what makes it self-improving.
How do voice agents learn from feedback?
Learning from feedback means turning real calls into changes. The raw material is production data: transcripts, audio, outcomes, and where callers got stuck. The loop reviews this, finds patterns, and updates the agent.
The feedback can be explicit or implicit. Explicit feedback is a human review, a thumbs-down, or a corrected response. Implicit feedback is behaviour: hang-ups, repeats, and escalations that signal a bad call. Techniques like reinforcement learning from human feedback formalise the explicit kind. Most production teams start simpler, with error analysis on failed calls feeding prompt and knowledge updates.
Can voice agents improve without retraining?
Yes, and this is the most practical point. Improvement does not always mean fine-tuning a model. Much of it happens above the model.
- Prompt optimization: refine instructions based on observed failures.
- Knowledge updates: add the answers the agent kept missing.
- Routing and guardrails: fix where the agent escalated wrong.
- Tool fixes: correct the calls that failed silently.
These changes are fast and reversible, which makes them the backbone of voice agent continuous improvement. Fine-tuning and retraining still have a place for deeper gains, but you do not need them to start. Adaptive voice agents often improve most from prompt and knowledge changes long before anyone touches model weights.
What a feedback loop looks like in production
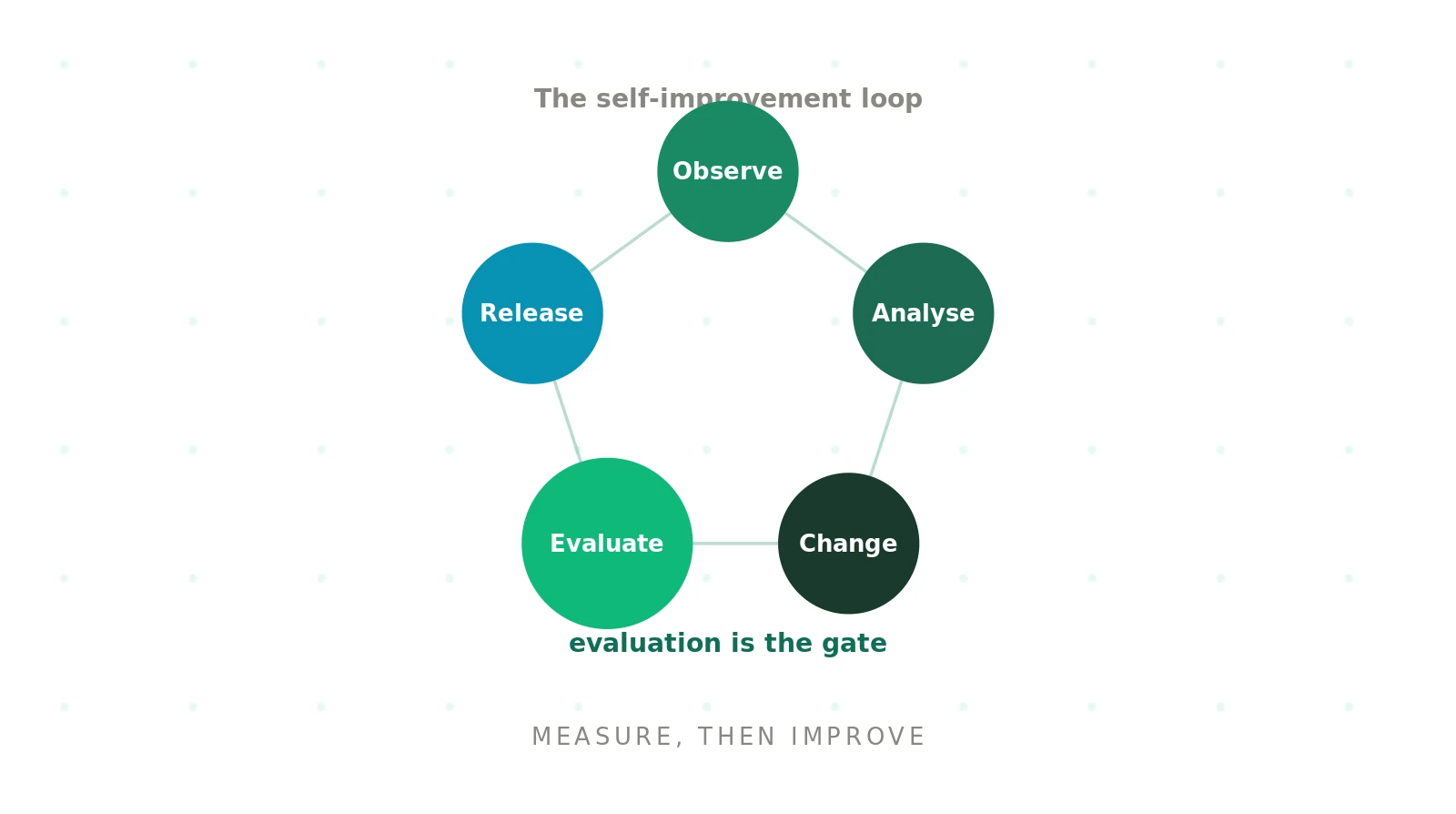
A working voice agent feedback loop has five stages, and it repeats.
1. Observe — Capture calls, outcomes, and failure signals from production.
2. Analyse — Run error analysis to find recurring failure patterns.
3. Change — Update prompts, knowledge, guardrails, or the model.
4. Evaluate — Test the change against scenarios before it ships.
5. Release — Roll out, then watch the same metrics to confirm the gain.
The loop is the product. A single fix is not self-improvement; a repeatable cycle is. Online learning can automate parts of this, but most teams keep a human in the loop for the change step, especially in regulated domains.
The risk: drift versus improvement
Here is the trap. A loop that changes the agent is not automatically a loop that improves it. Without a fixed yardstick, you cannot tell improvement from drift. A change that helps one call type can quietly break another.
This is why a baseline matters. You need a stable set of scenarios that you score every cycle. If the new version scores higher on the baseline, it improved. If it scores lower somewhere, that is a regression, not progress. The same discipline that catches model-update regressions catches self-improvement gone wrong. Our piece on why voice agents fail in production shows how silent drift accumulates.
Why evaluation is the feedback signal
This is the core idea. Self-improvement needs a signal that says better or worse, and that signal is evaluation. Without it, the loop is just change for its own sake.
Evaluation turns vague feedback into a number you can optimise. It tells the loop which change helped and by how much. This is the heart of eval-driven development: you define what good looks like, measure against it, and let the results guide each iteration. A self-improving agent without continuous evaluation is not improving in any way you can prove. It is just changing and hoping.
How to build a self-improving voice agent
Building one is mostly building the loop. The model is one part; the process around it is the rest.
1. Instrument production — Capture calls, outcomes, and failure signals.
2. Define a baseline — Build a fixed scenario set you score every cycle.
3. Analyse failures — Turn recurring failures into specific, fixable patterns.
4. Make scoped changes — Update prompts, knowledge, or the model deliberately.
5. Evaluate before release — Gate every change on the baseline and new scenarios.
6. Automate the cadence — Run the loop on a schedule, not just when something breaks.
Anthropic's note on building effective agents makes a related point: reliable systems come from disciplined process, not from hoping the model improves on its own. Automation helps, but the baseline is what keeps the loop honest.
Where self-improving voice agents pay off
Self-improvement compounds, so it pays off most in high-volume, long-lived deployments. A support line handling thousands of calls a week generates enough failure data to learn from quickly. Each cycle removes a class of failure, and the gains stack over months.
It pays off least in low-volume or short-lived agents. There is not enough data to learn from, and the loop's overhead outweighs the benefit. The honest test is whether you have the call volume and the review capacity to run the loop well. Self-improving ai agents are a commitment to a process, not a setting you switch on once and forget.
Self-improvement is a process, not a model
It is tempting to treat self-improvement as a model capability. It is not. The same model can sit inside a static agent or a self-improving one. The difference is the loop around it.
That loop needs owners. Someone reviews failures. Someone approves changes. Something scores each version against the baseline. Automation can carry the repetitive parts, but the judgement stays human in most production settings. Build the process first, and the model improvements follow. Skip the process, and even the best model plateaus the day it ships. Treat the loop as infrastructure you maintain, not a feature you enable once.
The risks and guardrails
Self-improving systems can get worse, not just better. The risks are real and worth naming.
- Silent drift: unmeasured changes degrade quality over time.
- Overfitting to recent calls: the agent tunes to last week and breaks on the long tail.
- Compounding errors: a bad change feeds the next cycle's data.
- Lost compliance: an optimisation quietly removes a required step.
The guardrails are straightforward. Keep a fixed evaluation baseline. Gate every change on it. Keep a human in the loop for high-stakes updates. And keep the change history, so you can roll back. Online learning without these guardrails is how a self-improving agent improves itself into a worse place. Reinforcement learning and automation amplify both good and bad changes, so the checks matter more, not less.
How to evaluate a self-improving voice agent
Evaluation is the part that makes self-improvement trustworthy, and it is exactly where Evalgent fits. Evalgent gives the loop its measurement layer. Scenarios form the fixed baseline you score every cycle. Profiles vary caller personas and accents so improvement is tested broadly, not just on easy calls. Metrics quantify each change with custom thresholds. Evaluations run the baseline as automated batches of synthetic callers on every iteration. Reviews let your team inspect what regressed when a change goes the wrong way.
The result is a loop you can trust: change, measure, keep or roll back. For the wider discipline, see the ai voice agent testing pillar and the synthetic callers guide. A self-improving agent is only as good as the evaluation that proves it improved.
Frequently asked questions
What is a self-improving voice agent?
A self-improving voice agent gets better over time by learning from production feedback, not just from a single training run. It reviews real calls, finds failures, and updates prompts, knowledge, or the model in a repeating loop. The key requirement is continuous evaluation, because without measurement the agent drifts rather than genuinely improves.
How do voice agents learn from feedback?
Voice agents learn from feedback by turning real calls into changes. Production data, including transcripts, outcomes, and failure signals like hang-ups and escalations, is analysed for patterns. Those patterns drive updates to prompts, knowledge, or the model. Feedback can be explicit, such as human review, or implicit, such as caller behaviour that signals a poor call.
Can voice agents improve without retraining?
Yes. Much improvement happens above the model, without retraining. Refining prompts, updating the knowledge base, fixing routing and guardrails, and correcting failed tool calls all raise quality and are fast and reversible. Fine-tuning and retraining offer deeper gains later, but most voice agent continuous improvement starts with prompt and knowledge changes, not model weights.
What is a feedback loop in voice ai?
A feedback loop in voice ai is the repeating cycle of observe, analyse, change, evaluate, and release. The agent captures production calls, error analysis finds failure patterns, the team updates the agent, the change is tested against a baseline, and then it ships under continued monitoring. The loop, not any single fix, is what makes an agent self-improving.
How do you build a self-improving voice agent?
Build a self-improving voice agent by building the loop around it. Instrument production to capture calls and failures, define a fixed scenario baseline, analyse failures into fixable patterns, make scoped changes to prompts or the model, and evaluate every change against the baseline before release. Automate the cadence so the loop runs on a schedule, not only after incidents.
What are the risks of self-improving agents?
The risks of self-improving agents include silent drift from unmeasured changes, overfitting to recent calls while breaking the long tail, compounding errors when a bad change feeds the next cycle, and lost compliance when an optimisation removes a required step. Guard against these with a fixed evaluation baseline, release gates, human review for high-stakes changes, and rollback.
How do you evaluate a self-improving voice agent?
Evaluate a self-improving voice agent against a fixed baseline of scenarios scored every cycle. Vary caller profiles so improvement is tested broadly, quantify each change with metrics and thresholds, and run the baseline as automated batches of synthetic callers. Compare each version to the last known-good run, and treat any drop as a regression to fix before release.
Do self-improving agents still need testing?
Yes, more than ever. A self-improving agent changes constantly, and every change can help or harm. Testing against a fixed baseline is the only way to tell improvement from drift. The evaluation loop is not separate from self-improvement; it is the signal that makes it real. Without it, the agent is changing and hoping, not improving.
Conclusion
Self-improving voice agents turn every call into a chance to get better. The loop, observe, analyse, change, evaluate, release, is what separates real improvement from random change.
The evaluation step is the one that matters most. Without a fixed baseline scored every cycle, you cannot tell whether your agent is improving or quietly drifting, so measure first and improve second. Build the loop, hold the baseline, and let the numbers decide what ships.
Related Articles
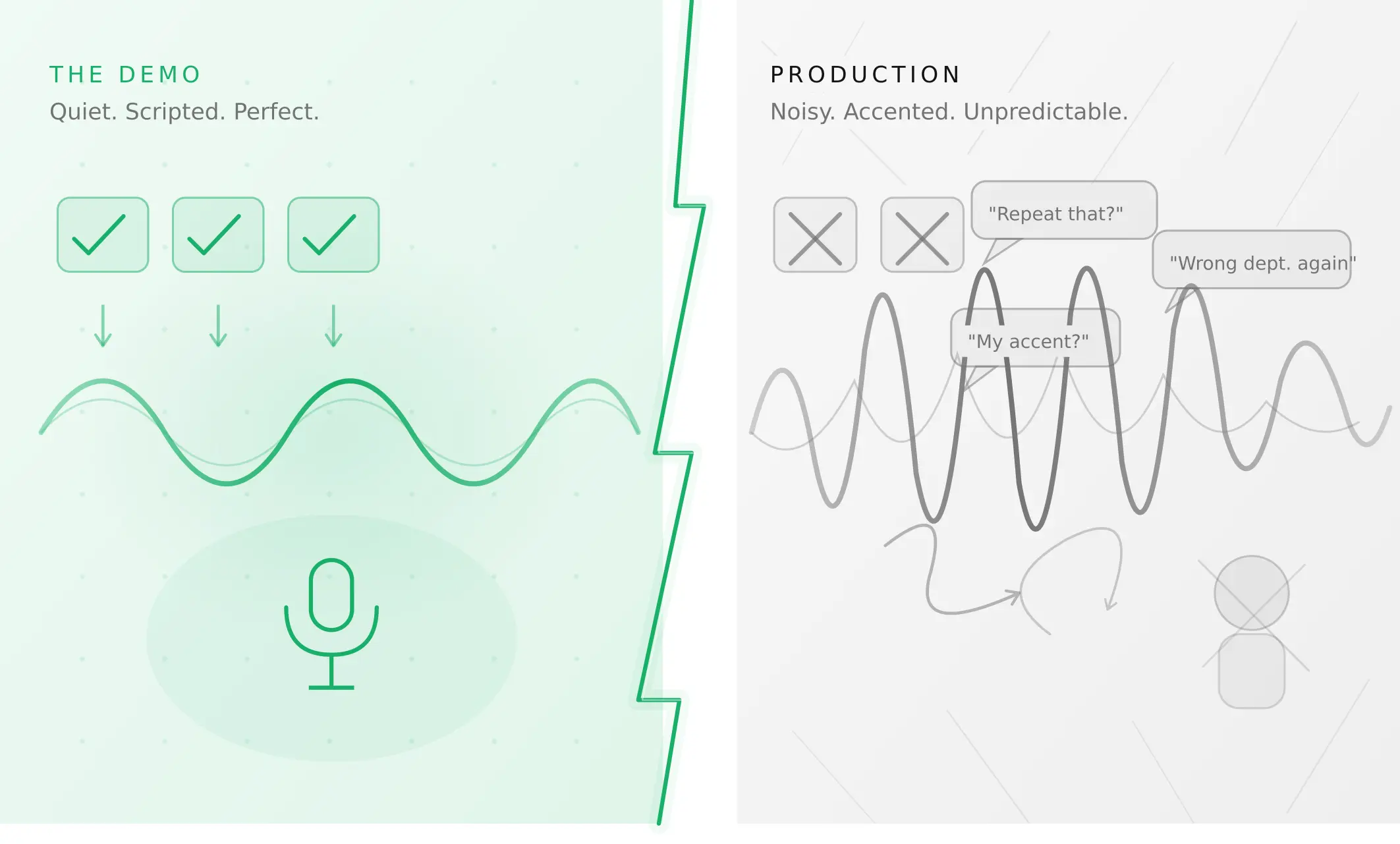
Why AI voice agents fail in production (and how to prevent it)
AI voice agents that ace demos still break in production. Learn the 5 root causes, how to test for each, and what production readiness actually means.
Read more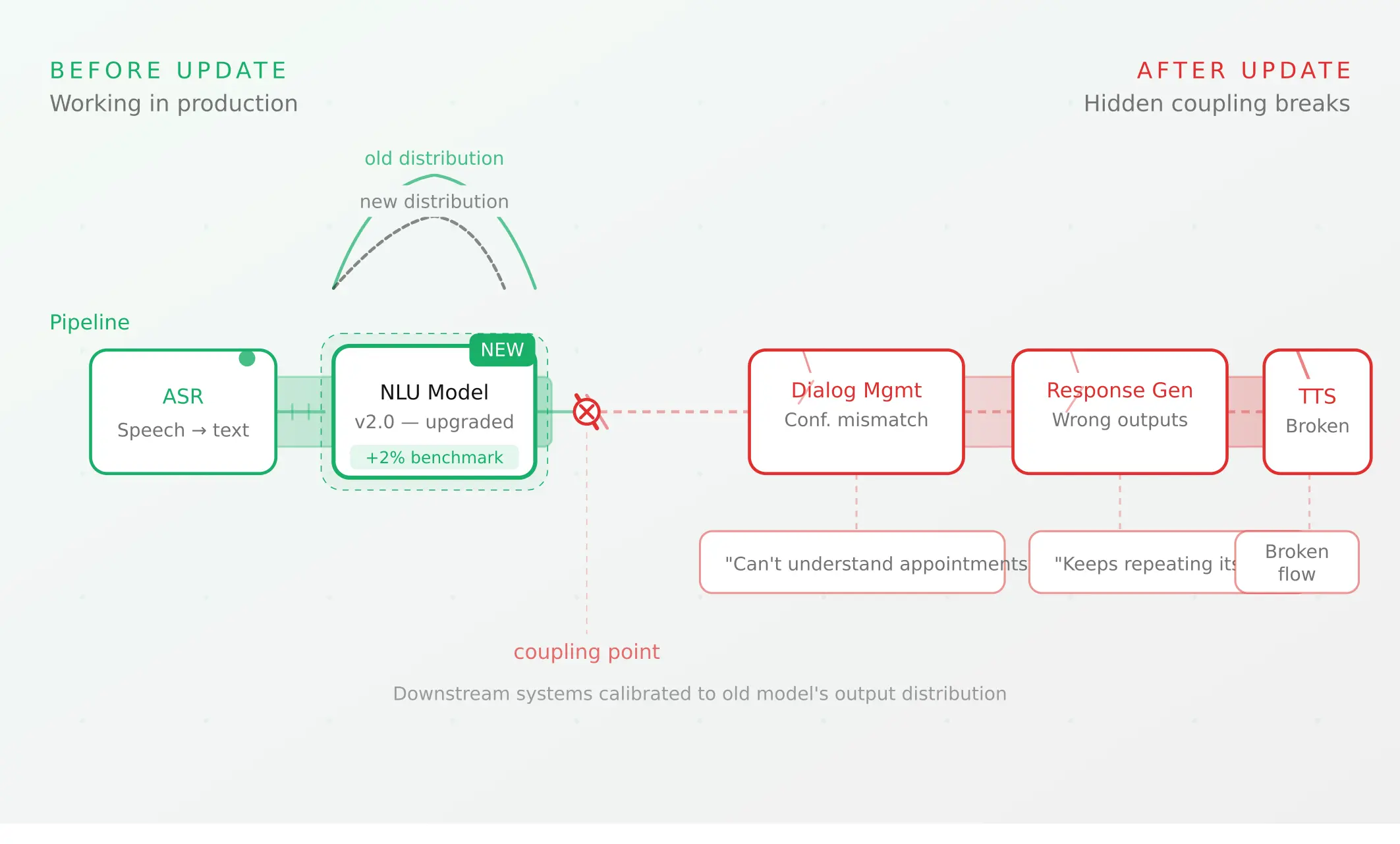
Voice agent regression testing: why LLM updates break production
Updating your LLM improves benchmarks but breaks production voice agents in 5 predictable ways. How to test after every model update and prevent regressions.
Read more